SSDUT智能技术系统方向大三专业课复习提纲,建议多背( •̀ ω •́ )✧
代码一定要会写啊kora!(#°Д°)
一、嵌入式系统的概念
1、 嵌入式计算机发展总结
- 嵌入式计算机是诞生于微处理器发展时代
- AI进一步驱动了嵌入式计算机的蓬勃发展
2、嵌入式系统的分类
- 按计算机的嵌入式应用和非嵌入式应用将其分为通用计算机和嵌入式计算机。
- 嵌入式计算机是计算机技术发展中的一种计算机存在的形式,是从计算机技术的发展中分离出来的。
3、我国嵌入式系统的行业定义
- 以应用为中心,以计算机技术为基础, 软件硬件可裁剪适应应用系统对功能、可靠性、成本、功耗严格要求的专用计算机系统。
4、嵌入式系统的组成结构
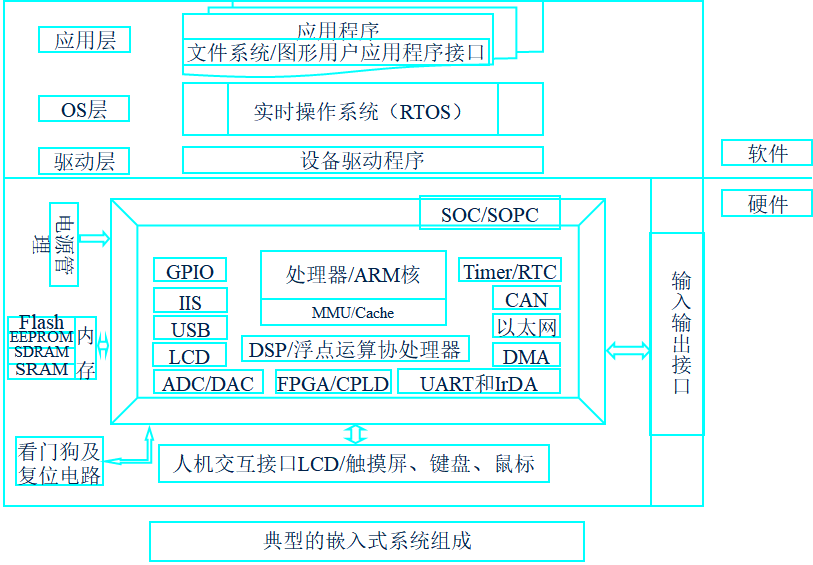
5、硬件基本结构
- 嵌入式系统的硬件架构,是以嵌入式处理器为中心,配置存储器、I/O设备、通信模块以及电源等必要的辅助接口组成。
- 嵌入式系统是“量身定做”的“专用计算机应用系统”。(Customize),非常经济、可靠。
6、嵌入式系统软件的层次结构
- 对于使用操作系统的嵌入式系统来说,结构三个层面:设备驱动层、实时操作系统(RTOS)、实际应用程序层。
7、BootLoader
- 对于PC机,启动初始化由BIOS完成的,对于嵌入式系统来说必须自行编写系统初始化程序,在嵌入式中称为BootLoader程序。
- 因此在系统加电复位后,处理器将首先执行 Boot Loader 程序。
二、ARM技术与ARM体系结构
1、计算机体系结构分类
两种典型的结构 :
- 冯·诺依曼结构:
- 将数据和指令都存储在存储器中的计算机。
- 计算系统由一个中央处理单元(CPU)和一个存储器组成。存储器拥有数据和指令,并且可以根据所给的地址对它进行读或写。
- 哈佛体系结构:
- 为数据和程序提供了各自独立的存储器。
- 程序计数器只指向程序存储器而不指向数据存储器,这样做的后果是很难在哈佛机上编写出一个自修改的程序 。
- 独立的程序存储器和数据存储器为数字信号处理提供了较高的性能。
- 冯·诺依曼结构:
ARM 7使用冯·诺依曼体系结构。
ARM 9使用哈佛体系结构。
2、ISA(Instruction-Set Architecture)指令集体系结构
- 不论从硬件工程师还是软件工程师的角度来看,处理器的设计都是至关重要的。因为支持复杂嵌入式系统设计的能力和设计开发的时间,在可用功能、芯片花费以及最重要的处理器性能上,都会受到指令集体系结构(ISA)的影响。
- 硬件工程师和软件工程师之间的一个桥梁:
- 硬件工程师根据ISA设计处理器
- 软件工程师根据ISA写程序
3、 ISA模型
- ISA模型
- 通用ISA模型
- 复杂指令集计算机(CISC):Intel x86
- 精简指令集系统(RISC):
- 由较少的指令组成的简单操作的体系结构
- 精简了每个可用操作的周期数的体系结构
- 通用ISA模型
4、ARM
ARM代表“高级精简指令集机器”
RISC,Reduced instruction set computer “精简指令集计算机”
- 优势:简单指令的执行速度比复杂指令平均快很多倍,提高了性能。
加载/存储(load/store)架构
- 程序员必须在数据被处理之前显式地把数据从存储器加载到寄存器。
- 同样,程序员必须在数据已被处理后显式地把输出数据存储到寄存器。
- 所有算数指令以寄存器内容作为输入和结果。
- 寄存器也可以用来存储临时或者中间结果。
三地址架构
- 一个单指令可以涉及三个寄存器
5、ARM7微处理器系列
- 低功耗的32位RISC处理器,冯·诺依曼结构。
- 具有嵌入式ICE-RT逻辑,调试开发方便。
- 3级流水线结构。
- 代码密度高,兼容16位的Thumb指令集。
- 对操作系统的支持广泛,包括Windows CE、Linux、Palm OS等。
- 指令系统与ARM9系列、ARM9E系列和ARM10E系列兼容,便于用户的产品升级换代。
- 主频最高可达130MIPS。
- 主要应用领域:工业控制、Internet设备、网络和调制解调器设备、移动电话等多种多媒体和嵌入式应用。
6、ARM内核模块
- ARM处理器一般都带有嵌入式追踪宏单元ETM(Embedded Trace Macro),它是ARM公司自己推出的调试工具。支持CPU运行过程中对实时数据进行仿真。
7、ARM流水线技术
- 流水线技术通过多个功能部件并行工作来缩短程序执行时间,提高处理器的效率和吞吐率。
- _ARM7_是冯·诺依曼结构,采用了典型的三级流水线,
- _ARM9_则是哈佛结构,采用五级流水线技术,
- _ARM11_则更是使用了_7_级流水线。
- 通过增加流水线级数,简化了流水线的各级逻辑,进一步提高了处理器的性能。
(1)ARM7三级流水线
ARM7系列内核采用了三条流水线的内核结构,三级流水线分别为取指(Fetch)、译码(Decode)、执行(Execute)
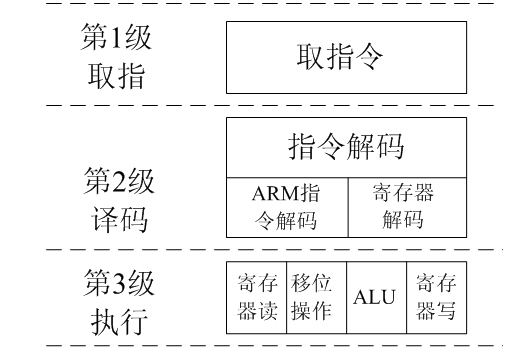
取指:将指令从存储器中取出,放入指令Cache中。
译码:由译码逻辑单元完成,是将在上一步指令Cache中的指令进行解释,告诉CPU将如何操作。
执行:这阶段包括移位操作、读通用寄存器内容、输出结果、写通用寄存器等。
需要注意的是,PC指向正被取指的指令而不是正在执行的指令
(2)ARM9内核结构
- ARM920是一款32位嵌入式RISC处理器内核。在指令操作上采用5级流水线 . * 取指:从指令Cache中读取指令。
- 译码:对指令进行译码,识别出是对哪个寄存器进行操作并从通用寄存器中读取操作数。
- 执行:进行ALU运算和移位操作,如果是对存储器操作的指令,则在ALU中计算出要访问的存储器地址。
- 存储器访问:如果是对存储器访问的指令,用来实现数据缓冲功能(通过数据Cache)。
- 寄存器回写:将指令运算或操作结果写回到目标寄存器中。

8、ARM处理器的工作模式
ARM处理器共有7种工作模式
用户模式:非特权模式,也就是正常程序执行的模式,大部分任务在这种模式下执行。
FIQ模式:也称为快速中断模式,支持高速数据传输和通道处理,当一个高优先级(fast)中断产生时将会进入这种模式。
IRQ模式:也称为普通中断模式,:当一个低优先级(normal)中断产生时将会进入这种模式。
SVC模式:称之为管理模式,它是一种操作系统保护模式。当复位或软中断指令执行时处理器将进入这种模式。
中止模式:当存取异常时将会进入这种模式,用来处理存储器故障、实现虚拟存储或存储保护。
未定义指令异常模式:当执行未定义指令时会进入这种模式,主要是用来处理未定义的指令陷阱,支持硬件协处理器的软件仿真,因为未定义指令多发生在对协处理器的操作上。
系统模式:使用和User模式相同寄存器组的特权模式,用来运行特权级的操作系统任务。
9、ARM 寄存器
ARM处理器共有37个寄存器,这些寄存器包括以下两类寄存器。
- 31个通用寄存器:包括程序计数器PC等,这些寄存器都是32位寄存器。
- 6个状态寄存器:状态寄存器也是32位的寄存器,但是目前只使用了其中的14位。
1 个用作PC( program counter)
1个用作CPSR(current program status register)
5个用作SPSR(saved program status registers)
30 个通用寄存器
10、程序状态寄存器

条件位:
- N = 1-结果为负,0-结果为正或0
- Z = 1-结果为0,0-结果不为0
- C = 1-进位,0-借位
- V =1-结果溢出,0结果没溢出
Q 位:
- 仅ARM 5TE/J架构支持
- 指示增强型DSP指令是否溢出
J 位:
- 仅ARM 5TE/J架构支持
- J = 1: 处理器处于Jazelle状态
中断禁止位:
- I = 1: 禁止 IRQ.
- F = 1: 禁止 FIQ.
T Bit:
- 仅ARM xT架构支持
- T = 0: 处理器处于 ARM 状态
- T = 1: 处理器处于 Thumb 状态
Mode位(处理器模式位):
- 0b10000 User
- 0b10001 FIQ
- 0b10010 IRQ
- 0b10011 Supervisor
- 0b10111 Abort
- 0b11011 Undefined
- 0b11111 System
11、程序指针PC (r15)
当处理器执行在ARM状态:
- 所有指令 32 bits 宽
- 所有指令必须 word 对齐
- 所以 pc值由bits [31:2]决定, bits [1:0] 未定义 (所以指令不能halfword / byte对齐).
当处理器执行在Thumb状态:
- 所有指令 16 bits 宽
- 所有指令必须 halfword 对齐
- 所以 pc值由bits [31:1]决定, bits [0] 未定义 (所以指令不能 byte对齐).
12、ARM异常处理
- 当正常的程序执行流程发生暂时的停止时,称之为异常。
- 例如处理一个外部的中断请求。在处理异常之前,当前处理器的状态必须保留,这样当异常处理完成之后,当前程序可以继续执行。
- 处理器允许多个异常同时发生,它们将会按固定的优先级进行处理。
(1)异常入口
ARM处理器的异常分为数据中止、快速中断请求、普通中断请求、预取指中止、软件中断、复位及未定义指令共7种 。
异常类型 处理器模式 优先级 向量表偏移 复 位 SVC 1 0x00000000 未定义指令 UND 6 0x00000004 软件中断SWI SVC 6 0x00000008 预取指中止 ABT 5 0x0000000c 数据中止 ABT 2 0x00000010 保留 / / 0x00000014 IRQ中断 IRQ 4 0x00000018 FIQ中断 FIQ 3 0x0000001c
(2)对异常的响应
- 当异常产生时, ARM core:
- 拷贝 CPSR 到 SPSR_< mode >
- 设置适当的 CPSR 位:
- 改变处理器状态进入 ARM 状态
- 改变处理器模式进入相应的异常模式
- 设置中断禁止位禁止相应中断 (如果需要)
- 保存返回地址到 LR_< mode >
- 设置 PC 位相应的异常向量
- 返回时, 异常处理需要:
- 从 SPSR _ < mode >恢复CPSR
- 从LR_< mode >恢复PC
- Note:这些操作只能在 ARM 态执行
13、外中断处理
ARM 有两级外部中断 FIQ,IRQ.
可是大多数的基于ARM 的系统有 >2个的中断源!
- 因此需要一个中断控制器(通常是地址映射的)来控制中断是怎样传递给ARM的。
- 在许多系统中,一些中断的优先级比其它中断的优先级高,他们要抢先任何正在处理的低优先级中断。
Note: 通常中断处理程序总是应该包含_清除中断源的代码_。
(1)FIQ vs IRQ
FIQ 和 IRQ 提供了非常基本的优先级级别。
在下边两种情况下,FIQs有高于IRQs的优先级:
- 当多个中断产生时,FIQ高于IRQ.
- 处理 FIQ时禁止 IRQs.
- IRQs 将不会被响应直到 FIQ处理完成.
FIQs 的设计使中断处理尽可能的快.
- FIQ 向量位于中断向量表的最末.
- 为了使中断处理程序可从中断向量处连续执行
- FIQ 模式有5个额外的私有寄存器 (r8-r12)
- 中断处理必须保护其使用的非私有寄存器
- 可以有多个FIQ中断源,但是考虑到系统性能应避免嵌套。
- FIQ 向量位于中断向量表的最末.
(2)中断重新使能的问题
当另外一个中断抢先当前中断时,如果程序员使用下边特殊的步骤来防止系统状态丢失 ,中断是可以嵌套:
- 保存IRQ状态下的LR( LR_IRQ )
- 保存IRQ状态下的SPSR(SPSR_IRQ)
当中断可重入时,在中断处理程序中使用“BL…”必须特别小心:
- 如果第二个中断产生,BL调用的返回地址 (LR_irq) 可能被冲掉,子程序将错误的返回 – 导致无限循环!
解决方法是在使用“BL…”之前改变模式来避免 LR_irq 被冲掉
- 通常使用“System”模式 ( 这时 BL 使用 LR_usr)
在处理程序结束,必须:
- 切换回 IRQ 模式
- 禁止中断 (来避免在恢复SPSR_irq 到一个临时的寄存器中后它被冲掉).
(3)软中断
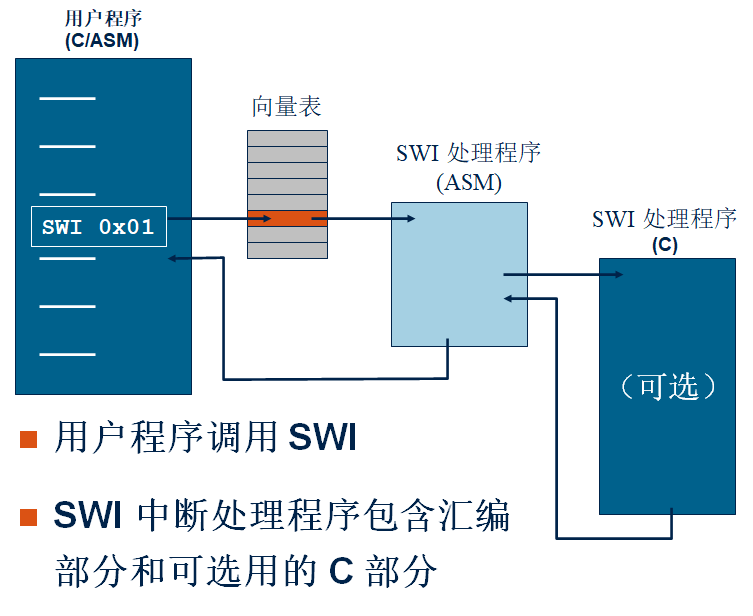
(4)SWI调用
汇编中, SWI 调用使用“SWI 中断号”实现:
SWI 0x24
小心在汇编中如果SWI 调用时处于Supervisor模式将会冲掉LR_svc.
- 例如:在SWI处理程序中的二级调用
- 解决方法: 在SWI调用之前对LR_svc 压栈保护
C 中, 使用关键词 “__swi” 来定义一个软中断函数
(5)存取SWI号
SWI 指令按相应的格式译码:
- ARM 态格式:

Thumb 态格式:

(6)存取SWI参数
- 汇编中,存取调用者设置的寄存器即可.
- 在返回之前,修改寄存器的值,传回参数给调用者.
- 传参数给C, 通常采用压栈的方法.
- 将参数压栈
- 给调用的函数传递一个指向这些参数的指针
- 也可以通过将参数值写回到适当的堆栈位置,将参数传回
(7)复位
- Reset 处理程序执行的动作取决于不同的系统. 例如它可以:
- 设置异常向量
- 初始化存储器系统 (MMU/PU)
- 初始化所有需要的模式的堆栈和寄存器
- 初始化所有 C 所需的变量
- 初始化所有I/O设备
- 使能中断
- 改变处理器模式或/和状态
- 调用主应用程序
(8)未定义指令
下列情况将引起未定义指令异常:、
- ARM 试图执行一真正的未定义指令
- ARM 遇到一协处理器指令,可是系统中的协处理器硬件并不存在
- ARM 遇到一协处理器指令,系统中协处理器硬件也存在,可是ARM 不是在超级用户模式(privileged mode)
- 例如:操作协处理器15(cp15) - ARM cache 控制器
解决方法:
- 在处理程序中执行软协处理器仿真
- 禁止在非超级用户模式下操作
- 报告错误并退出
(9)预取异常
不论异常是发生在 ARM 还是Thumb 状态下,导致预取异常的指令地址在 lr-4 处.
处理方法取决于存储器管理策略
- 有存储器管理的系统 (e.g. demand paged virtual memory)
- 修正问题 (e.g. enable correct memory page)
- 返回并重新执行预取异常的指令( SUBS pc,lr,#4 )
- 没有存储器管理的系统
- 通常表示一个致命的错误
- 报告错误 (如果可能) 然后退出
- 有存储器管理的系统 (e.g. demand paged virtual memory)
(10)数据异常
导致异常的指令的地址在 lr-8 处.
处理方法取决于存储器管理策略
有存储器管理的系统( demand-paged virtual memory)
如果使用了 MMU ,数据异常的地址在 MMU 的 “Fault Address” 寄存器中
修正问题(enable correct page of memory)
返回并重新执行数据异常的指令
SUBS pc,lr,#8
没有存储器管理的系统
- 通常表示一个致命的错误
- 报告错误 (如果可能) 然后退出
(11)异常返回地址
- ARM 状态:
- 在异常产生的时候内核设置 LR_mode = PC - 4.
- 处理程序需要调整 LR_mode (取决于是哪一个异常发生了),以便返回到正确的地址
- Thumb 状态:
- 处理器根据发生的异常自动修改存在 LR_mode 中的地址
- 不论异常产生时的状态如何,处理器确保处理程序的ARM 返回指令能返回到正确的地址(和正确的状态)
(12)从SWIs和未定义指令返回

(13)从FIQs和IRQs和预取异常返回

(14)从数据异常返回

(15)异常返回指令
使用一数据处理指令:
相应的指令取决于什么样的异常
> 设置CPSR, “S” bit > PC做为目的寄存器
在特权模式不仅仅更新PC,而且 拷贝SPSR 到 CPSR
从SWI 和 Undef异常返回
MOVS pc,lr从FIQ, IRQ 和 预取异常(Prefect Abort)返回
SUBS pc,lr,#4从数据异常( Data Abort)返回
SUBS pc,lr,#8如果 LR之前被压栈的话使用LDM“ ^”
LDMFD sp!,{pc}^
14、 存储方式与存储器映射机制
- ARM处理器地址空间大小为4G字节,这些字节的单元地址是一个无符号的32位数值,其取值范围为0~(2^32)-1。各存储单元地址作为32位无符号数,可以进行常规的整数运算。
- 当程序正常执行时,每执行一条ARM指令,当前指令计数器加4个字节;每执行一条Thumb指令,当前指令计数器加2个字节。
(1)数据存储格式
- 小端存储格式
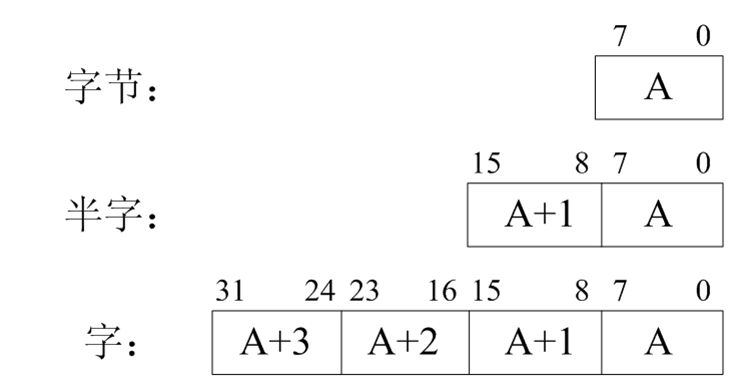
- 大端存储格式
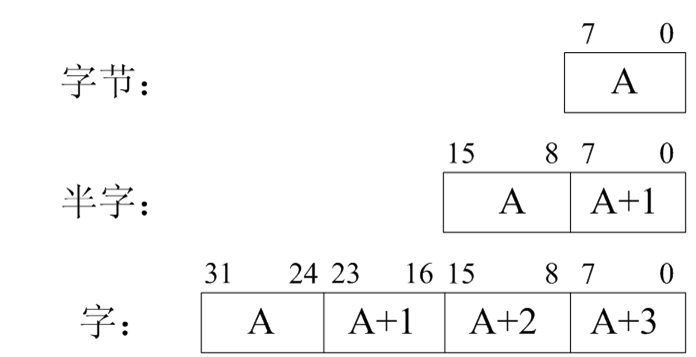
ARM支持大小端格式存取数据
(2)非对齐存储器地址访问问题分析
1* 非对齐的指令预取操作
- 如果是在ARM状态下将一个非对齐地址写入PC,则数据在写入PC时数据的第0位和第1位被忽略,最终PC的bit[1:0]为0;
- 如果是在Thumb状态下将一个非对齐地址写入PC,则数据在写入PC时数据的第0位被忽略,最终PC的bit[0]为0。
2* 非对齐地址内存的访问操作
- 对于LOAD/STORE操作,系统定义了下面3种可能的结果:
- 执行结果不可预知;
- 忽略字单元地址低两位的值,即访问地址为字单元;
- 忽略半字单元最低位的值,即访问地址为半字单元。这种忽略是由存储系统自动实现的。
15、ARM流水线技术分析
(1)ARM7流水线技术
为增加处理器指令流的速度,ARM7 系列使用3级流水线.
- 允许多个操作同时处理,比逐条指令执行要快。
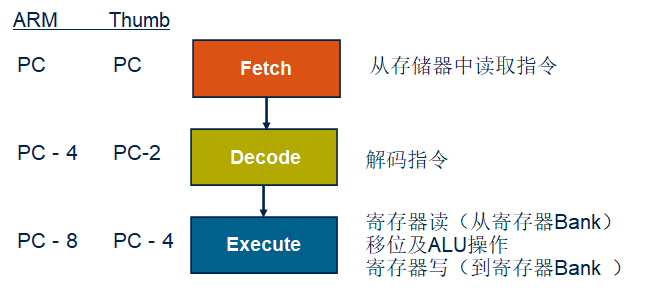
- 允许多个操作同时处理,比逐条指令执行要快。
PC指向正被取指的指令,而非正在执行的指令
最佳流水线

(2)ARM9TDMI流水线
与ARM7的区别
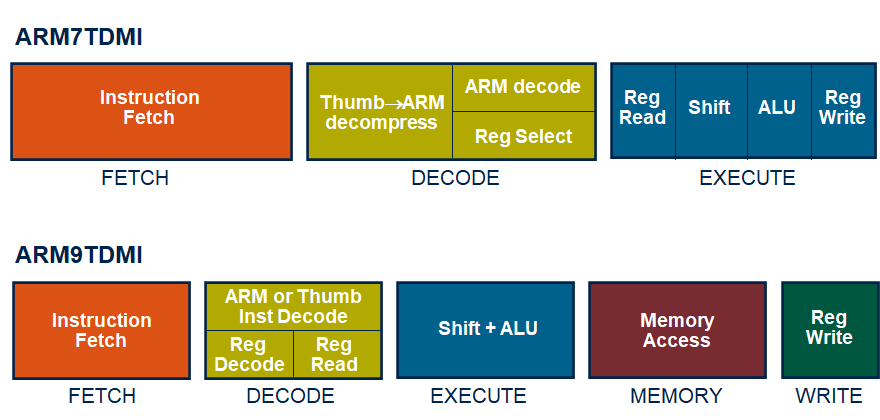
最佳流水线

LDR互锁
- LDR指令之后立即跟一条数据操作指令,由于使用了相同的寄存器,将会导致互锁 。
LDM互锁
- 在LDM期间,有并行的存储器访问和回写周期
三、ARM指令集寻址方式
1、ARM指令的编码格式
(1)一般编码格式
- 每条ARM指令占有4个字节,其指令长度为32位
指令条件码
| 二进制码 | 指令 | 意义 | 条件 |
|---|---|---|---|
| 0000 | EQ | 相等 | Z=1 |
| 0001 | NE | 不相等 | Z=0 |
| 0010 | CS/HS | 无符号大于等于 | C=1 |
| 0011 | CC/LO | 无等号小于 | C=0 |
| 0100 | MI | 负数 | N=1 |
| 0101 | PL | 非负数 | N=0 |
| 0110 | VS | 上溢出 | V=1 |
| 0111 | VC | 没有上溢出 | V=0 |
| 1000 | HI | 无符号数大于 | C=1且Z=0 |
| 1001 | LS | 无符号数小于等于 | C=0或Z=1 |
| 1010 | GE | 有符号数大于等于 | N=1且V=1或N=0且V=0 |
| 1011 | LT | 有符号数小于 | N=1且V=0或N=0且V=1 |
| 1100 | GT | 有符号数大于 | Z=0且N=V |
| 1101 | LE | 有符号数小于等于 | Z=1或N!=V |
| 1110 | AL | 无条件执行 |
2、数据处理指令寻址方式
(1)数据处理指令第2操作数的构成方式
1* 立即数方式
每个立即数由一个8位的常数进行32位循环右移偶数位得到,其中循环右移的位数由一个4位二进制的两倍表示。即:
<immediate>=immed_8进行32位循环右移(2* rotate_4)位
ARM处理器中,立即数必须是对应8位位图格式,即立即数是由一个8bit的常数在16位或32位的寄存器中循环移动(向左或向右都可以)偶数位得到的。合法的立即数必须能够找到得到它的那个常数,否则这个立即数就是非法的。


2* 寄存器方式
- 操作数即为寄存器的数值,如:
1 | MOV R3,R2 |
3*寄存器移位方式
- 寄存器移位方式
- 操作数为寄存器的数值做相应的移位而得到。在ARM指令中移位操作包括逻辑左移、逻辑右移、算术左移、算术右移、循环右移和带扩展的循环右移
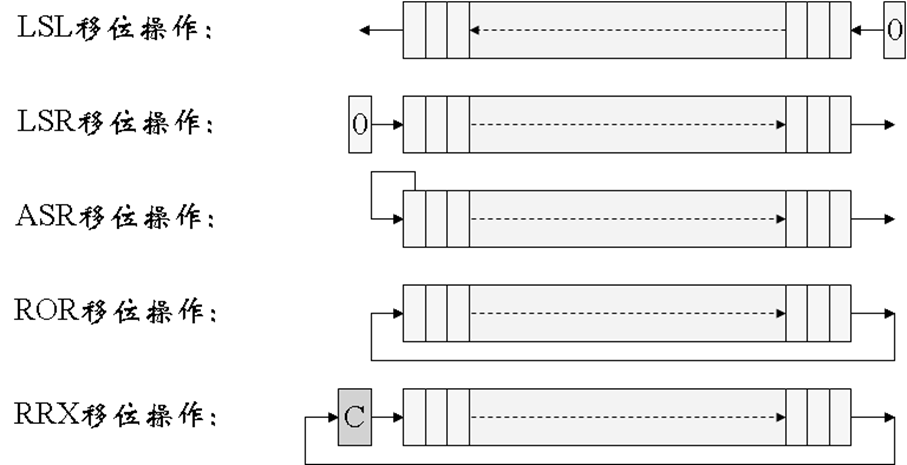
- 操作数为寄存器的数值做相应的移位而得到。在ARM指令中移位操作包括逻辑左移、逻辑右移、算术左移、算术右移、循环右移和带扩展的循环右移
(2)具体寻址类型
1* 第二操作数为立即数
- 汇编语法格式:
#<immediate>
I位bits[25] 设置为1
eg.
1 | MOV R0, 0xFC0 ;R0←0xFC0 |
在以上三条指令中,第二个源操作数即为立即数,要求以“#”为前缀,对于以十六进制表示的立即数,还要求在“#”后加上“0x”。
2* 第二操作数为寄存器
汇编语法格式:
<Rm>
I位bits[25] 设置为0
1 | ADD R0, R1, R2 ; R0←R1 + R2 |
3* 第二操作数为寄存器移位方式,且移位的位数为一个5位的立即数
- 汇编语法格式:
<Rm>,<shift> #<shift_imm>
4* 第二操作数为寄存器移位方式,且移位数值放在寄存器中
- 汇编语法格式:
<Rm>,<shift> <Rs>
5* 第二操作数为寄存器进行RRX移位得到
汇编语法格式:
<Rm>,RRX

(3)寄存器寻址
- 寄存器寻址
- 利用寄存器中的数值作为操作数,这种寻址方式是各类微处理器经常采用的一种方式,也是一种执行效率较高的寻址方式。
(4)第二操作数为寄存器
- 在ARM指令的数据处理指令中参与操作的二操作数为寄存器型时,在执行寄存器寻址操作时,可以选择是否对第二操作数进行移位,即
Rm,{<shift>},其中Rm称为第二操作数寄存器,<shift>用来指定移位类型(LSL,LSR,ASL,ASR,ROR或RRX)和移位位数。移位位数可以是5位立即数(#<#shift>)或寄存器(Rs)。在指令执行时将移位后的内容作为第二操作数参与运算。例如指令:
1 | ADD R3,R2,R1,LSR #2 ;R3←R2 + R1÷4 |
(5)Load/Store指令寻址
- Load/Store指令是对内存进行存储/加载数据操作的指令,根据访问的数据格式的不同,将这类指令的寻址分为字、无符号字节的Load/Store指令寻址和半字、有符号字节Load/Store指令寻址两大类。
1* 寄存器间接寻址
- 寄存器间接寻址就是以寄存器中的值作为操作数的地址,而操作数本身存放在存储器中。例如以下指令:
1 | LDR R0,[R1] ;R0 ←[R1] |
(6)基址加变址寻址
- 基址变址寻址就是将寄存器(该寄存器一般称作基址寄存器)的内容与指令中给出的地址偏移量相加,从而得到一个操作数的有效地址。变址寻址方式常用于访问某基地址附近的地址单元。
- 前变址法:基地址寄存器中的值和地址偏移量先作加减运算,生成的操作数作为内存访问的地址。
- 后变址法:将基地址寄存器中的值直接作为内存访问的地址进行操作,内存访问完毕后基地址寄存器中的值和地址偏移量作加减运算,并更新基地址寄存器。
(7)字、无符号字节寻址
- 汇编指令语法格式为:
1 | LDR {<cond>}{B}{T}<Rd>,<addressing_mode> |


1* Addressing_mode中的偏移量为立即数
- 前变址不回写形式:
1 |
- 前变址回写形式:
1 | ! |
- 后变址回写形式:
1 | ,#+/-<immed_offset> |

| W | P | 汇编语法格式 |
|---|---|---|
| 0 | 1 | [ |
| 1 | 0 | [ |
| 1 | 1 | [ |
2* Addressing_mode中的偏移量为寄存器的值
- 前变址不回写形式:
1 |
- 前变址回写形式:
1 | ! |
- 后变址回写形式:
1 | ,+/-<Rm> |

| W | P | 汇编语法格式 |
|---|---|---|
| 0 | 1 | [ |
| 1 | 0 | [ |
| 1 | 1 | [ |
偏移量通过寄存器移位得到
- 前变址不回写形式:
1 | [<Rn>,+/-<Rm>,<shift> |
- 前变址回写形式:
1 | [<Rn>,+/-<Rm>,<shift> |
- 后变址回写形式:
1 | ,+/-<Rm>,<shift>#shift_amount |

| W | P | 汇编语法格式 |
|---|---|---|
| 0 | 1 | [ |
| 1 | 0 | [ |
| 1 | 1 | [ |
(8)半字、有符号字节寻址
这类指令可用来加载有符号字节、加载有符号半字、加载/存储无符号半字。
Load/Store指令对半字、有符号字节操作指令编码格式如下:

加载有符号字节到寄存器:
1 | LDR {<cond>}SB <Rd>,<addressing_mode> |
- 加载有符号半字到寄存器:
1 | LDR {<cond>}SH <Rd>,<addressing_mode> |
- 加载无符号半字到寄存器:
1 | LDR {<cond>}H <Rd>,<addressing_mode> |
- 存储无符号半字到内存:
1 | STR {<cond>}H <Rd>,<addressing_mode> |
1* Addressing_mode中的偏移量为立即数
- 前变址不回写形式:
1 |
- 前变址回写形式:
1 | ! |
- 后变址回写形式:
1 | ,#+/-<immed_offset8> |

| W | P | 汇编语法格式 |
|---|---|---|
| 0 | 1 | [ |
| 1 | 0 | [ |
| 1 | 1 | [ |
2* Addressing_mode中的偏移量为寄存器的值
- 前变址不回写形式:
1 |
- 前变址回写形式:
1 | ! |
- 后变址回写形式:
1 | ,+/-< Rm > |

| W | P | 汇编语法格式 |
|---|---|---|
| 0 | 1 | [ |
| 1 | 0 | [ |
| 1 | 1 | [ |
(9)批量Load/Store指令寻址方式
- ARM指令系统提供了批量Load/Store指令寻址方式,即通常所说的多寄存器寻址,也就是一次可以传送几个寄存器的值,允许一条指令最多传送16个寄存器。
1* 编码格式
- 批量加载:
1 | LDM {<cond>}<addr_mode> <Rn> {!}, <register>{^} |
- 批量存储:
1 | STM {<cond>}<addr_mode> <Rn> {!}, <register>{^} |

- register_list表示要加载或存储的寄存器列表,bit[15:0]可以表示16个寄存器,如果某位为1,则该位的位置作为寄存器的编号,此寄存器参预加载或存储。
- S用于恢复CPSR和强制用户位。当程序计数器PC包含在LDM指令的register_list中,且S为1时,则当前模式的SPSR被拷贝到CPSR中,使处理器的程序返回和状态的恢复成为一个原子操作。如果register_list中不包含程序计数器PC,S为1则加载或存储的是用户模式下的寄存器组。
注意事项:
- 指令中寄存器和连续内存地址单元的对应关系:
- 编号低的寄存器对应内存低地址单元,编号高的寄存器对应内存高地址单元。
2* 内存操作
后增IA (Increment After) :每次数据传送后地址加4;
先增IB (Increment Before) :每次数据传送前地址加4 ;
后减DA (Decrement After) :每次数据传送后地址减4 ;
先减DB (Decrement Before) :每次数据传送前地址减4 ;
它们与指令编码中P、U的对应关如下表所示
- LDM/STM的地址变化方式
addr_mode P U D A 0 0 I A 0 1 D B 1 0 I B 1 1

3* 堆栈操作
- 堆栈是一种数据结构
- 先进先出
- 使用一个堆栈指针的专用寄存器只是当前位置
- ARM 中是R13
- 根据堆栈指针的位置可以分为:
- 满堆栈(Full Stack):
- 当堆栈指针指向最后压入堆栈的数据时;
- 空堆栈(Empty Stack):
- 当堆栈指针指向下一个将要放入数据的空位置时;
- 根据堆栈的生成方式,又可以分为递增堆栈和递减堆栈:
- 递增堆栈(Ascending Stack) :
- 当堆栈由低地址向高地址生成时;
- 递减堆栈(Decending Stack) :
- 当堆栈由高地址向低地址生成时;
4* 块拷贝与栈操作的对应关系
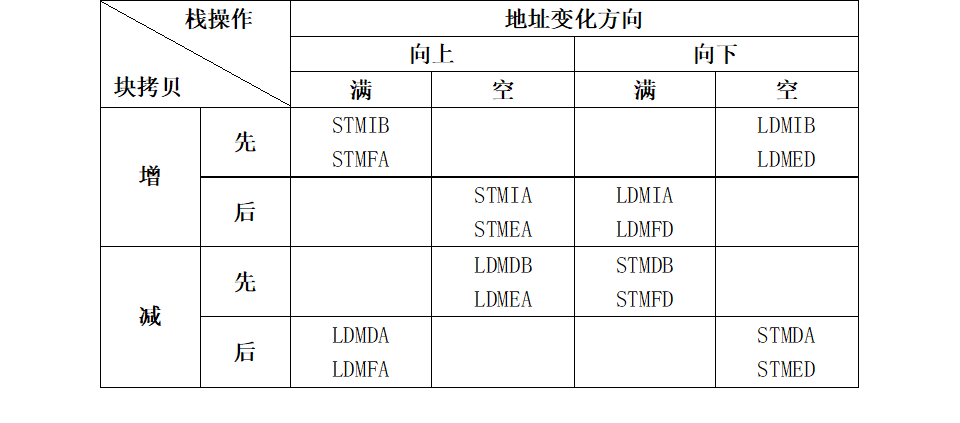
(7)协处理器指令寻址方式
1 | <opcode>{<cond>}{L} <coproc>,<CRd>,<addressing_mode> |
- 其中:
- opcode为指令操作码;
- coproc为协处理器名称;
- addressing_mode为指令寻址模式。
1* 内存地址索引格式

- 前变址不回写形式:
1 | [<Rn>,#+/-<imm_offset8>* 4] |
- 前变址回写形式:
1 | [<Rn>,#+/-<imm_offset8>* 4]! |
- 后变址回写形式:
1 | ,#+/-<imm_offset8>* 4 |
2* 内存地址非索引格式
- 这种指令寻址汇编语法格式为
1 | ,<user-define> |

四、ARM指令集系统
1、数据处理指令
(1)基本数据处理指令
- ARM基本的数据处理指可以分为4类:数据传送指令、算术运算指令、逻辑运算指令和比较指令。
- ARM基本的数据处理指令汇编指令语法格式:
1 | <opcode>{<cond>}{S}<Rd>,<Rn>,<operand2> |


1* 数据传输指令
1. MOV指令
- MOV指令的汇编语法格式为
1 | MOV{cond}{S} Rd, operand2 |
- 将第二操作数operand2表示的数据传送到目标寄存器Rd中;如果指令包含后缀“S”,则根据操作结果或移位情况更新CPSR中的相应条件标志位。
2. MVN指令
- MVN指令的汇编语法格式为
1 | MVN{cond}{S} Rd, operand2 |
- 将第二操作数operand2表示的数据按位取反后传送到目标寄存器Rd中;如果指令包含后缀“S”,则根据操作结果或移位情况更新CPSR中的相应条件标志位。
2* 算数运算指令
1. ADD加法指令
- ADD加法指令的汇编语法格式为
1 | ADD{cond}{S} Rd, Rn, operand2 |
- ADD指令将operand2表示的数据与寄存器Rn中的值相加,并把结果传送到目标寄存器
<Rd>中;如果指令包含后缀“S”,则根据操作结果更新CPSR中的相应条件标志位。
2. ADC带C标志位的加法指令
1 | ADC{cond}{S} Rd, Rn, operand2 |
- 功能:ADC带C标志位的加法指令将operand2表示的数据与寄存器Rn中的值相加,再加上CPSR中的C条件标志位的值,并把结果传送到目标寄存器Rd中;如果指令包含后缀“S”,则根据操作结果更新CPSR中的相应条件标志位。该指令可以实现两个高于32位的数据相加运算。
3. SUB减法指令
1 | SUB{cond}{S} Rd, Rn, operand2 |
- 功能:SUB指令从寄存器Rn中减去operand2表示的数值,并把结果传送到目标寄存器
<Rd>中;如果指令包含后缀“S”,则根据操作结果更新CPSR中的相应条件标志位。
注意事项:当指令包含后缀“S”时,如果减法运算有借位,则C=0,否则C=1。
4. SBC带C标志位的减法指令
1 | SBC{cond}{S} Rd, Rn, operand2 |
- SBC指令从寄存器
<Rn>中减去operand2表示的数值,再减去寄存器CPSR中C条件标志位的反码,并把结果传送到目标寄存器Rd中;如果指令包含后缀“S”,则根据操作结果更新CPSR中的相应条件标志位。该指令可以实现两个高于32位的数据相减运算。
5. RSB逆向减法指令
1 | RSB{cond}{S} Rd, Rn, operand2 |
- 功能:RSB指令从第2操作数operand2表示的数值中减去寄存器Rn 值,并把结果传送到目标寄存器Rd中;如果指令包含后缀“S”,则根据操作结果更新CPSR中的相应条件标志位。
6. RSC带C标志位的逆向减法指令
1 | RSC{cond}{S} Rd,Rn, operand2 |
- 功能:RSC指令从operand2表示的数值中减去寄存器Rn 值,再减去寄存器CPSR中 C条件标志位的反码,并把结果传送到目标寄存器Rd中;如果指令包含后缀“S”,则根据操作结果更新CPSR中的相应条件标志位。
3* 逻辑运算指令
1. AND与逻辑运算指令
1 | AND{cond}{S} Rd, Rn, operand2 |
- 功能:AND指令将operand2表示的数值与寄存器Rn 的值按位做逻辑与操作,并把结果保存到目标寄存器Rd中;如果指令包含后缀“S”,则根据操作结果更新CPSR中的相应条件标志位。
2. ORR或逻辑运算指令
1 | ORR{cond}{S} Rd, Rn, operand2 |
- 功能:ORR指令将operand2表示的数值与寄存器Rn的值按位做逻辑或操作,并把结果保存到目标寄存器Rd中;如果指令包含后缀“S”,则根据操作结果更新CPSR中的相应条件标志位。
3. EOR异或逻辑运算指令
1 | EOR{cond}{S} Rd, Rn, operand2 |
- 功能:EOR指令将operand2表示的数值与寄存器Rn的值按位做逻辑异或操作,并把结果保存到目标寄存器Rd中;如果指令包含后缀“S”,则根据操作结果更新CPSR中的相应条件标志位。EOR指令可用于将寄存器中某些位的值取反。
4. BIC清除逻辑运算指令
1 | BIC{cond}{S} Rd, Rn, operand2 |
- 功能:BIC指令将寄存器Rn的值与operand2表示的数值的反码按位做逻辑与操作,并把结果保存到目标寄存器Rd中
4* 比较指令
- 比较指令没有目标寄存器,只用作更新条件标志位,不保存运算结果,指令后缀无需加“S”。在程序设计中,根据操作的结果更新CPSR中相应的条件标志位,后面的指令就可以根据CPSR中相应的条件标志位来判断是否执行。
1. CMP相减比较指令
1 | CMP{cond} Rn, operand2 |
- 功能:CMP指令将寄存器Rn的值减去operand2表示的数值,根据操作结果和寄存器移位情况更新CPSR中的相应条件标志位。
2. CMN负数比较指令
1 | CMN{cond} Rn, operand2 |
- 功能:CMN指令将寄存器Rn的值加上operand2表示的数值,根据操作结果和寄存器移位情况更新CPSR中的相应条件标志位。
3. TST位测试指令
1 | TST{cond} Rn, operand2 |
- 功能:TST指令将寄存器Rn的值与operand2表示的数值按位作逻辑“与”操作,根据操作结果和寄存器移位情况更新CPSR中的相应条件标志位。
4. TEQ相等测试指令
1 | TEQ{cond} Rn, operand2 |
- 功能:TEQ指令将寄存器Rn的值与operand2表示的数值按位作逻辑“异或”操作,根据操作结果和寄存器移位情况更新CPSR中的相应条件标志位。
(2)乘法指令
- ARM乘法指令完成2个寄存器中数据的乘法,按照保存结果的数据长度可以分为两类:一类为32位的乘法指令,即乘法操作的结果为32位;另一类为64位的乘法指令,即乘法操作的结果为64位。
1* 32位乘法指令

1. MUL
1 | MUL{cond}{S} Rd, Rm, Rs |
- MUL指令实现两个32位的数(可以为无符号数,也可为有符号数)的乘积(Rm * Rs )并将结果存放到一个32位的寄存器Rd中;如果指令包含后缀“S”,则根据操作结果更新CPSR中的相应条件标志位。
2. MLA
1 | MLA{cond}{S} Rd, Rm, Rs, Rn |
- MLA指令实现两个32位的数(可以为无符号数,也可为有符号数)的乘积,再将乘积(Rm * Rs )加上第3个操作数Rn,并将结果存放到一个32位的寄存器Rd中;如果指令包含后缀“S”,则根据操作结果更新CPSR中的相应条件标志位。
2* 64位乘法指令

1. UMULL
1 | UMULL{cond}{S} RdLo, RdHi, Rm, Rs |
- UMULL指令实现两个32位无符号数的乘积,乘积结果的高32位存放到一个32位的寄存器的RdHi,乘积结果的低32位存放到另一个32位的寄存器的RdLo;如果指令包含后缀“S”,则根据操作结果更新CPSR中的相应条件标志位。
2. UMLAL
1 | UMLAL{cond}{S} RdLo, RdHi, Rm, Rs |
- UMLAL指令将两个32位无符号数的64位乘积结果与由(RdHi: RdLo)表示的64位无符号数相加,加法结果的高32位存放到寄存器RdHi中,加法结果的低32位存放到寄存器RdLo中;如果指令包含后缀“S”,则根据操作结果更新CPSR中的相应条件标志位。
3. SMULL
1 | SMULL{cond}{S} RdLo, RdHi, Rm, Rs |
- SMULL指令实现两个32位有符号数的乘积,乘积结果的高32位存放到一个32位的寄存器的RdHi,乘积结果的低32位存放到另一个32位的寄存器的RdLo;如果指令包含后缀“S”,则根据操作结果更新CPSR中的相应条件标志位。
4. SMLAL
1 | SMLAL{cond}{S} RdLo, RdHi, Rm, Rs |
- SMLAL指令将两个32位有符号数的64位乘积结果与由(RdHi: RdLo)表示的64位无符号数相加,加法结果的高32位存放到寄存器RdHi中,加法结果的低32位存放到寄存器RdLo中;如果指令包含后缀“S”,则根据操作结果更新CPSR中的相应条件标志位。
(3)杂类的数据处理指令
从ARM V5版本指令系统开始支持杂类的数据处理指令CLZ(Count Leading Zeros,前导零计数指令),用于计算32位寄存器高位中“0”的个数。

指令的汇编语法格式:
1 | CLZ <cond> <Rd>,<Rm> |
- CLZ指令不影响条件码标志。
- 示例解析:
1 | MOV R4, |
2、ARM分支指令
分支指令用于实现程序流程的跳转,在ARM程序中有两种方法可以实现程序流程的跳转:
使用专门的分支指令。
直接向程序计数器PC写入跳转地址值。
跳转指令
- ARM指令集中的跳转指令可以完成从当前指令向前或向后的32MB的地址空间的跳转,包括以下4条指令:
- B 跳转指令
- BL 带返回的跳转指令
- BLX 带返回和状态切换的跳转指令
- BX 带状态切换的跳转指令
通过向程序计数器PC写入跳转地址值,可以实现在4GB的地址空间中的任意跳转,在跳转之前结合使用MOV LR,PC等类似指令,能够保存程序的返回地址值,从而实现在4GB连续地址空间的子程序调用。
1* 分支指令B
- 分支指令B可以实现跳转到指定的地址执行程序。
- 指令的汇编语法格式如下:
1 | B{<cond>} <target_address> |

在指令的汇编语法中target_address这个目标地址的计算方法是:将指令中的24位带符号的补码立即数扩展为32位;将此32位数左移两位将得到的值写入到程序计数器PC中,即跳转到目标地址。能够实现跳转的范围为-32MB~+32MB。
- B指令是最简单的跳转指令。一旦遇到一个 B 指令,ARM 处理器将立即跳转到给定的目标地址,从那里继续执行。注意存储在跳转指令中的实际值是相对当前PC值的一个偏移量,而不是一个绝对地址,它的值由汇编器来计算。它是24位有符号数,左移两位后有符号扩展为 32 位,表示的有效偏移为 26 位(前后32MB的地址空间)。如:
1 | B Label /*程序无条件跳转到标号Label处执行*/ |
2* 带链接的分支指令BL
- 带链接的分支指令BL可以实现跳转到指定的地址执行程序,同时BL指令还将程序计数器PC的值保存到LR寄存器中。
- 指令的汇编语法格式如下:
1 | BL{<cond>} <target_address> |

L决定是否保存返回地址。当有L时,指令将下一条指令地址保存到LR寄存器中;当无L时同B指令仅执行跳转,当前PC寄存器的值将不会保存到LR寄存器中。从指令的编码可以看出,B与BL指令的唯一区别是bit[24],当bit[24]=0是B指令,当bit[24]=1是BL指令。
BL跳转指令编码中signed_immed_24的含义同B指令。
3* 带状态切换的跳转指令 BX
- BX指令跳转到指令中所指定的目标地址,目标地址处的指令既可以是ARM指令,也可以是Thumb指令。
- 指令的汇编语法格式如下:
1 | BX{<cond>} <Rm> |

BX指令跳转到Rm指定的地址执行程序,如果Rm的bit[0]为1,则跳转时自动将CPSR中的标志位T置位,目标地址的代码为Thumb代码;如果Rm的bit[0]为0,则跳转时自动将CPSR中的T标志位清0,目标地址的代码为ARM代码。
如果 LSB=1, 则进入 Thumb 指令处理模式; 如果 LSB=0, 则进入 ARM 指令处理模式。
4* 带链接和状态切换的跳转指令 BLX
- BLX指令从ARM指令集跳转到指令中所指定的目标地址,并将处理器的工作状态由ARM状态切换到Thumb状态,该指令同时将程序计数器PC的当前内容保存到链接寄存器R14中。
1. 由程序标号给出目标地址
- 这种形式的BLX指令汇编语法格式如下:
1 | BLX <target_address> |

目标地址target_address的计算方法:先对指令中定义的有符号24位偏移量用符号位扩展为32位,并将该32位数左移2位,然后将其加到程序计数器PC中,H位(bit[24])加到目标地址的第1位(bit[1]),目标地址总是Thumb指令。跳转的范围为-32MB~+32MB。
2. 寄存器的内容作为目标地址
- 这种形式的BLX指令汇编语法格式如下:
1 | BLX{<cond>} <Rm> |

BLX指令跳转到Rm指定的地址执行程序,如果Rm的bit[0]为1,则跳转时自动将CPSR中的标志位T置位,目标地址的代码为Thumb代码;如果Rm的bit[0]为0,则跳转时自动将CPSR中的T标志位清0,目标地址的代码为ARM代码。
3、加载/存储指令
- 用于操作32位的字类型数据以及8位无符号的字节类型数据;
- 用于操作16位半字类型数据和8位的有符号字节类型数据。
(1)加载/存储字、无符号字节指令
1* LDR/STR指令
1 | LDR{cond} Rd,<addressing> |
- LDR指令用于从内存中将一个32位的字数据读取到指令中的目标寄存器中。对于小端内存模式,指令读取的低地址字节数据存放在目标寄存器的低8位(bits[7:0]);对于大端的内存模式,指令读取的低地址字节数据存放在目标寄存器的高8位(bits[31:24])。
- STR指令用于将一个32位寄存器中的字数据写入到指令中指定的内存单元。对于小端内存模式,寄存器的低8位存放在低地址字节单元;对于大端内存模式,寄存器的低8位存放在高地址字节单元。
1 | LDR{cond}T Rd,<addressing> |
LDRT/STRT是用户模式下的字数据加载/存储指令,当在特权极的处理器模式下使用本指令时,内存系统将该操作当作一般用户模式下的内存访问操作。这种指令在用户模式下使用无效,在特权模式下只能使用前变址形式。


2* LDRB/STRB指令
1 | LDR{cond}B Rd,<addressing> |
- LDRB指令用于从内存中将一个8位的字节数据读取到指令中的目标寄存器低8位(bits[7:0])中,寄存器的高24位(bits[31:8])清零。
- STRB指令用于将一个寄存器的低8位(bits[7:0])写入到指令中指定的内存地址字节单元。
1 | LDR{cond}BT Rd,<addressing> |
LDRBT/STRBT是用户模式下的字数据加载/存储指令,当在特权极的处理器模式下使用本指令时,内存系统将该操作当作一般用户模式下的内存访问操作。这种指令在用户模式下使用无效,在特权模式下只能使用前变址形式。


(2)半字、有符号字节访问指令
- 半字数据访问指令用于内存中的数据与寄存器低16位数据进行操作,有符号字节访问指令可实现向寄存器加载8位的有符号字节数据。
- 对于向寄存器加载无符号半字数据,寄存器的高16位bits[31:16]清零;
- 对于向寄存器加载有符号半字数据,寄存器的高16位bits[31:16]用符号位扩展为32位;
- 对于向寄存器加载有符号字节数据,寄存器的高24位bits[31:8]用符号位扩展为32位。

1 | LDR{cond}H Rd,<addressing > |
S、H取值含义

ARM微处理器所支持批量数据加载/存储指令可以一次性实现一片连续的存储器单元和多个寄存器之间进行传送数据。
批量数据加载指令用于将一片连续的存储器中的数据传送到多个寄存器中,批量数据存储指令能够实现将多个寄存器中的内容一次性的存放到一片连续的存储器中。
4、批量加载/存储指令
(1)基本批量字数据加载/存储指令
- 批量加载:
1 | LDM {<cond>}<addr_mode> <Rn> {!}, <registers> |
- 批量存储:
1 | STM {<cond>}<addr_mode> <Rn> {!}, <registers> |
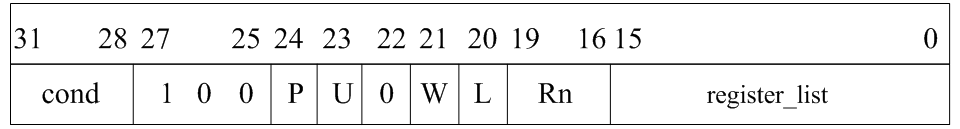

- 注意事项:
- Rn不允许为程序计数器PC(R15)
- 指令中寄存器和连续内存地址单元的对应关系:编号低的寄存器对应内存低地址单元,编号高的寄存器对应内存高地址单元。
- 如果指令中基址寄存器
<Rn>在寄存器列表<registers>中,而且指令中寻址方式指定指令执行后更新基址寄存器<Rn>的值,则指令执行会产生不可预知的结果。
(2)用户模式下的批量字数据加载/存储指令
- 用户模式下的批量字数据加载/存储指令操作实现的操作是:即使处理器工作在特权模式下,存储系统也将访问看成是处理器在用户模式下,因此所加载/存储的寄存器组为用户模式下的寄存器。该指令寄存器列表中不包含程序计数器PC,不允许对基地址寄存器回写操作。
- 用户模式下的批量字数据加载/存储指令汇编语法格式为
- 批量加载:
1 | LDM {<cond>}<addr_mode> <Rn> , <registers_without_pc>^ |
- 批量存储:
1 | STM {<cond>}<addr_mode> <Rn> , <registers_without_pc>^ |

(3)带PSR操作的批量字数据加载指令
- 在带PSR操作的批量字数据加载指令中,程序计数器PC包含在指令寄存器列表中。
- 该指令将数据从连续的内存单元中读取到指令中寄存器列表中的各寄存器中。它同时将目前处理器模式对应的SPSR寄存器内容复制到CPSR寄存器中。
- 批量加载:
1 | LDM {<cond>}<addressing_mode> <Rn> {!}, <registers_with_pc>^ |
- 批量存储:
1 | STM {<cond>}<addressing_mode> <Rn> {!}, <registers_with_pc>^ |

5、交换指令
- ARM指令支持原子操作,主要是用来对信号量的操作,因为信号量操作的要求是作原子操作,即在一条指令中完成信号量的读取和修改操作。
(1)字数据交换指令
- SWP是对字数据操作指令,用于将一个寄存器Rn为地址的内存字数据单元的内容读取到一个寄存器
<Rd>中,同时将另一个寄存器Rm的内容写入到该内存单元中。
1 | SWP{<cond>} <Rd>, <Rm>, |

(2)字节数据交换指令
- SWPB是对字节操作指令,用于将一个寄存器Rn为内存地址的字节数据单元的内容读取到一个寄存器Rd中,寄存器Rd的高24设置为0,同时将另一个寄存器Rm的低8位数值写入到该内存单元中
1 | SWP{<cond>}{B} <Rd>, <Rm>, |

6、程序状态寄存器PSR访问指令
(1)读程序状态寄存器指令
- MRS指令用于将状态寄存器的内容传送到通用寄存器中。这是程序获得程序状寄存器PSR数据的唯一方法。
1 | MRS {<cond>} <Rd>, CPSR |

(2)写程序状态寄存器指令
- MSR指令用于将通用寄存器的内容或一个立即数传送到程序状态寄存器中,实现对程序状态寄存器的修改。
1 | MSR {<cond>} CPSR_<fields>, < operand2> |

- fields设置状态寄存器中需要操作的位域。状态寄存器分为4个8位的域:
- bits[31:24]为条件标志位域,用f表示;
- bits[23:16]状态位域,用s表示;
- bits[15:8]扩展位域,用x表示;
- bits[7:0]控制位域,用c表示;
- 第二操作数operand2的构成形式有以下两种形式:
<immediate>为将要传送到状态寄存器中的立即数;
<Rm>寄存器包含将要传送到状态寄存器中的数据。- R(bit[22])为0时,写CPSR;R(bit[22])为1时,写SPSR。
7、协处理器操作指令
- 协处理器操作是ARM处理器对协处器进行管理,也就是ARM处理器的相关操作通过发送指令给协处理器,让协处理器来完成。ARM微处理器最多可支持16个协处理器,用于各种协处理操作。
(1)协处理器数据操作指令
- 协处理器数据操作指令CDP用法:ARM处理器通知ARM协处理器执行特定的操作,若协处理器不能成功完成特定的操作,则产生未定义指令异常。
1 | CDP{<cond>} <Cp_num>,<opcode_1>,<CRd>,<CRn>,<CRm>,{<opcode_2>} |

- cond为指令执行的条件码。当
<cond>忽略时指令为无条件执行。 - CRd为目标寄存器的协处理器寄存器。
- CRn为存放第1个源操作数的协处理器寄存器。
- CRm为存放第2个源操作数的协处理器寄存器。
- Cp_num为协处理器的编码。
- opcode1为协处理器将执行操作的第一操作码。
- opcode2为协处理器将执行操作的第二操作码。(可选)
(2)协处理器加载/存储指令
- 协处理器的加载/存储指令可以用来实现ARM处理器与协处理器之间的数据传输,共有两条:协处理器数据加载指令LDC和协处理器数据存储指令STC。
- 协处理器的加载存储指令汇编语法格式如下:
1 | LDC{<cond>}{L} <coproc>,<CRd>,<addressing_mode> |

- Rn为ARM处理器的通用寄存器,它用作基地址寄存器。
- 需要注意的是,汇编语法格式中的L是表示传输的数据为长整数,其对应指令编码中的“N”。而指令二进制编码中的“L”是用来区别LDC和STC指令。
1* 协处理器数据加载指令LDC
- LDC指令用于将一系列连续的内存单元的数据读取到协处理器的寄存器中,并由协处理器来决定传输的字数。如果协处理器不能成功的执行该操作,将产生未定义的指令异常中断。
eg.
1 | LDC P3,CR4,[R0] ;将ARM处理器的寄存器R0所指向的存储器中的字数据传送到协处理器P3的CR4 寄存器中 |
2* 协处理器数据存储指令STC
- STC指令将协处理器的寄存器中的数据写入到一系列连续的内存单元中,并由协处理器来决定传输的字数。如果协处理器不能成功的执行该操作,将产生未定义指令异常中断。
(3)ARM寄存器与协处理器寄存器数据传输指令
ARM寄存器与协处理器寄存器数据传输指令用来实现ARM通用寄存器与协处理器寄存器之间的数据传输,共有两条: 1. ARM寄存器到协处理器寄存器的数据传送指令MCR
- 协处理器寄存器到ARM寄存器的数据传送指令MRC。
ARM寄存器与协处理器寄存器数据传输指令汇编语法格式如下:
1 | MCR{<cond>} <Cp_num>,<opcode1>,<Rd>,<CRn>,<CRm>{,<opcode2>} |


1* ARM寄存器到协处理器寄存器的数据传送指令MCR
- MCR指令将ARM处理器的寄存器中的数据传送到协处理器的寄存器中。如果协处理器不能成功的执行该操作,将产生未定义的指令异常中断。
eg.
1 | MCR p6,2,R0,CR1,CR2,4 ;指令将ARM寄存器R0中数据传送到协处理器p6的寄存器中,其中R0是存放源操作数的ARM寄存器,CR1和CR2是作为目标寄存器的协处理器寄存器,操作码1为2,操作码2为4 |
2* 协处理器寄存器到ARM寄存器的数据传送指令MRC
- MRC指令将协处理器的寄存器中的数据传送到ARM处理器的寄存器中。如果协处理器不能成功的执行该操作,将产生未定义的指令异常中断
eg.
1 | MRC p10,3,R3,CR3,CR4,6 ; 指令将协处理器p10寄存器中的数据传送到ARM寄存器R3中,其中R3是存放目标操作数的ARM寄存器,CR3和CR4是作为目标寄存器的协处理器寄存器,操作码1为3,操作码2为6 |
8、异常产生指令
ARM处理器所支持的异常产生指令有两条:
软中断指令SWI
断点调试指令BKPT(用于ARM V5及以上的版本)
(1)软中断指令
- SWI(SoftWare Interrupt)指令用于产生软件中断,它将处理器置于监控模式(SVC),从地址0x08开始执行指令。
- ARM通过这种机制实现用户模式对操作系统中特权模式的程序调用,也就是使用户程序调用操作系统的系统程序成为可能。
1 | SWI{<cond>} <immed_24> |

- 操作系统在SWI的异常处理程序中提供相应的系统服务,指令中24位的立即数指定用户程序调用系统例程的类型,相关参数通过通用寄存器传递。
- 执行过程:
- 将SWI后面指令地址保存到R14_svc;
- 将CPSR保存到SPSR_svc;
- 进入监控模式,将CPSR[4:0]设置为0b10011的将CPSR[7]设置为[1],禁止IRQ;
- 将PC设置为0x08,并且开始执行那里的指令。
- 返回时:MOVS PC,R14
(2)断点中断指令
- BKPT (BreakPoinT)指令产生软件断点中断,可用于程序的调试。当BKPT指令执行时,处理器停止执行下面的指令并进入相应的BKPT入口程序
1 | BKPT <immed_16> |

- immed_16为16位的立即数,此立即数被调试软件用来保存额外的断点信息。
五、ARM汇编伪指令与伪操作
1、汇编语言伪指令
- 伪指令是ARM处理器支持的汇编语言程序里的特殊助记符,它不在处理器运行期间由机器执行,只是在汇编时将被合适的机器指令代替成ARM或Thumb指令,从而实现真正的指令操作。
(1)伪指令的意义
- 伪指令不是指令,伪指令和指令的根本区别是经过编译后会不会生成机器码。
- 伪指令的意义在于指导编译过程。
- 伪指令是和具体的编译器相关的
(2)汇编中的一些符号
- @用来做注释。可以在行首也可以在代码后面同一行直接跟,和C语言中//类似
- #做注释,一般放在行首,表示这一行都是注释而不是代码。
- :以冒号结尾的是标号
- . 点号在gnu汇编中表示当前指令的地址
- #立即数前面要加#或$,表示这是个立即数
(3)常用伪指令
1 | .global _start @ 给_start外部链接属性 |
(4)ARM汇编语言伪指令
1* 大范围地址读取伪指令LDR
- LDR伪指令将一个32位的常数或者一个地址值读取到寄存器中,可以看作是加载寄存器的内容。
1 | LDR{cond} register , = expression |
- 如果加载的常数符合MOV或MVN指令立即数的要求,则用MOV或MVN指令替代LDR伪指令。
- 如果加载的常数不符合MOV或MVN指令立即数的要求,汇编器将常量放入内存文字池,并使用一条程序相对偏移的LDR指令从内存文字池读出常量。
文字池:文字池的本质就是ARM汇编语言代码节中的一块用来存放常量数据而非可执行代码的内存块。
2* 中等范围地址读取伪指令ADRL
- 它将基于PC相对偏移的地址值或基于寄存器相对偏移的地址值读取到寄存器中。
1 | ADRL{cond} register , = expression |
- 汇编器在处理源程序时,ADRL伪指令被两条具有ADRL等同功能的ARM指令(通常用ADD或SUB指令)替代。
- 如果不能用两条指令实现ADRL伪指令的功能,则编译器报告错误,编译失败。
3* 小范围地址读取伪指令ADR
- 它将基于PC相对偏移的地址值或基于寄存器相对偏移的地址值读取到寄存器中。当地址是字节对齐时,取值范围为-255~+255
1 | ADR{cond} register , = expression |
4* 空操作伪指令NOP
- NOP是空操作伪指令,在汇编时将会被替代成ARM中的空操作 .
(5)Thumb汇编语言伪指令
1* 大范围地址读取伪指令LDR
- LDR伪指令将一个32位的常数或者一个地址值读取到寄存器中,可以看作是加载寄存器的内容。其语法格式如下:
1 | LDR register , = expression |
2* 小范围地址读取伪指令ADR
- ADR为小范围地址读取伪指令,它将基于PC相对偏移的地址值读取到寄存器中。偏移量必须是正数并小于1KB。
1 | ADR register , = expression |
- 相当于PC寄存器或其它寄存器的长转移。
- 汇编器在处理源程序时,ADR伪指令一条具有ADR等同功能的thumb指令(通常用ADD或SUB指令)替代。
- 如果不能用一条指令实现ADR伪指令的功能,则编译器报告错误,编译失败。
3* 空操作伪指令NOP
- NOP是空操作伪指令,在汇编时将会被替代成ARM中的空操作(也就是什么也没做)指令,例如可能为:“MOV R0,R0”
1 | NOP |
- 空操作伪指令可用于延时操作。
2、汇编语言伪操作
伪操作(Directive)是ARM汇编语言程序里的一些特殊的指令助记符,其作用主要是为完成汇编程序做各种准备工作,对源程序运行汇编程序处理,而不是在计算机运行期间由处理器执行。
伪操作只是汇编过程中起作用,一旦汇编结束,伪操作也就随之消失。
目前常用的编译环境有2种:
ADS/SDT、RealView MDK等ARM公司推出的开发工具
GNU ARM开发工具
3、GNU ARM汇编伪操作
- 在嵌入式系统开发中,不可避免的要使用GNU工具,要进行嵌入式LINUX的移植与开发,其中与硬件直接相关的部分要用汇编语言来编程。
(1)符号定义伪操作
1* 常量定义伪操作.equ或.set
- 语法格式:
1 | .equ symbol, expr |
- 其中:
- symbol 为要指定的名称,它可以是以前定义过的符号;
- expr 表示数字常量或程序中的标号。
2* 常量定义伪操作.equiv
- 语法格式:
1 | .equiv symbol, expr |
- 其中:
- symbol 为要指定的名称,它不可以是以前定义过的符号;
- expr 表示数字常量或程序中的标号。
3* 声明全局常量伪操作.global或.globl
- 语法格式:
1 | .global symbol |
- 其中:
- symbol 为要声明的全局变量名称
4* 声明外部常量伪操作.extern
- 语法格式:
1 | .extern symbol |
- 其中:
- symbol 为要声明的外部变量名称
(2)数据定义伪操作
1* 字节定义.byte
- 语法格式:
1 | .byte expr {, expr }… |
- 其中:
- expr 数字表达式或程序中的标号。
2* 半字定义.hword或.short
- 语法格式:
1 | .hword expr {, expr }…. |
- 其中:
- expr 数字表达式或程序中的标号。
3* 字定义.word或.int或.long
- 语法格式:
1 | .word expr {, expr }…. |
- 其中:
- expr 数字表达式或程序中的标号。
4* 字符串定义.ascii和.asciz或.string
- 语法格式:
1 | .ascii expr {, expr }… |
- 其中:
- expr 表示字符串。
5* 双字定义.quad
- 语法格式:
1 | .quad expr {, expr }… |
- 其中:
- expr 数字表达式。
6* 四字定义.octa
- 语法格式:
1 | .octa expr {, expr }… |
- 其中:
- expr 数字表达式。
7* 单精度浮点数定义.float或.single
- 语法格式:
1 | .float expr {, expr }…. |
- 其中:
- expr 为32位的 IEEE 单精度浮点数。
8* 双精度浮点数定义.double
- 语法格式:
1 | .double expr {, expr }… |
- 其中:
- expr 为32位的 IEEE 双精度浮点数
9* 重复内存单元定义.fill
- 语法格式:
1 | .fill repeat {, size}{, value} |
- 其中:
- repeat 重复填充的次数;
- size 每次所填充的字节数;
- value 所填充的数据。
10* 零填充字节内存单元定义.zero
- 语法格式:
1 | .zero size |
- 其中:
- size 所分配的0填充字节数
11* 固定填充字节内存单元定义.space或.skip
- 语法格式:
1 | .space size {, value} |
- 其中:
- size 所分配的字节数
12* 声明数据缓冲池.ltorg
- 语法格式
1 | .ltorg |
(3)汇编与反汇编代码控制伪操作
1* 指令集类型标识伪操作
1 | .arm |
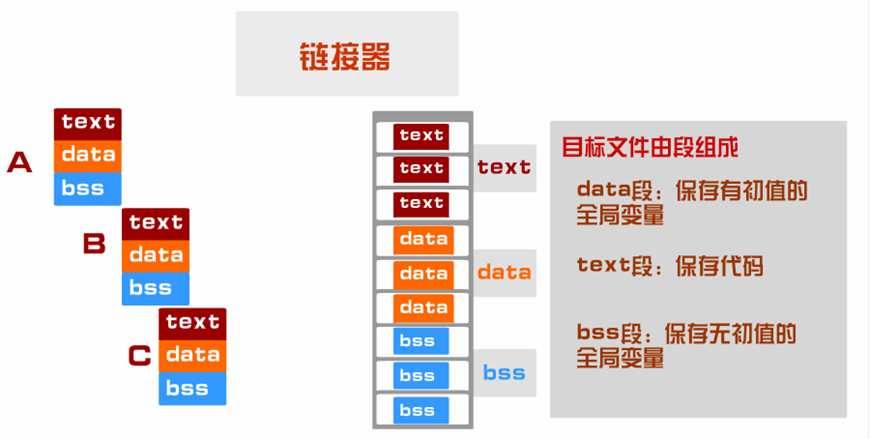
2* 段属性定义伪操作
- 语法格式如下:
1 | .section expr |
- 其中:
- expr 为段属性,可以是.text、.data、.bss中的一个。
3* 段起始声明伪操作
- 具体的语法格式如下:
1 | .text |
4* 对齐方式设置伪操作.align或.balign
- 语法格式:
1 | .align {alignment} {, fill} |
- 其中:
- alignment 是一个数值表达式,用于指定对齐方式,其取值在0~15范围内;
- fill 用来指定进行填充的数据。
5* 代码位置设置伪操作.org
- 语法格式:
1 | .org offset {, expr} |
- 其中:
- offset 是一个数值表达式,表示地址偏移量;
- expr 用来指定进行填充的数据。
(4)预定义控制伪操作
- 汇编器在对程序代码进行编译时,会根据汇编控制伪操作的定义情况对程序进行编译,常用的有条件编译、宏定义和文件包含
1* 条件编译伪操作.if
- 语法格式:
1 | logical_expression |
2* 宏定义伪操作.macro
- 语法格式:
1 | .macro |
3* 文件包含伪操作.include
- .include伪操作用于将一个源文件包含到当前的源文件中,所包含的文件在.include指令的位置处进行汇编处理。
- 语法格式:
1 | "file_name" |
六、汇编语言程序设计
1、ARM编译环境下汇编语句
- ARM编译环境下进行汇编语言程序设计的格式
- 汇编语句中的符号规则
(1)ADS环境下ARM汇编语句格式
1 | {symbol} {instruction} {;comment} |
(2)ADS编译环境下汇编语句中符号规则
1* 符号命名规则
- 符号由大小写字母、数字、下划线组成,且符号是区分大小写的;
- 局部标号可以用数字开头,其他的标号不能;
- 符号在其作用范围内必须是唯一的;
- 程序中的符号不要与指令助记符或者伪操作同名。
2* 常量
- 十进制数,如535、246。
- 十六进制数,如0x645、0xff00。
- n_XXX, n表示n进制数,从2~9,XXX是具体的数字。例如:8_3777
- 字符常量用一对单引号括起来,包括一个单字符或者标准C中的转义字符。例如‘A’、‘\n’。
- 字符串常量由一对双引号以及由它括住的一组字符串组成,包括标准C中的转义字符。
- 如果需要使用双引号”或字符$ ,则必须用””和$$代替
3* 变量
- 数字变量—汇编器对-n和232-n不做区别
- 字符串变量—字符串变量最大长度为512字节
- 逻辑变量—{FALSE}和{TRUE}
4* 字符串表达式操作
1. 取符串的长度LEN
- 语法格式:
1 | A |
- 功能说明:返回字符串A的长度。
2. CHR
- 语法格式:
1 | A |
- 功能说明:将A(A为某一字符的ASCII值)转换为单个字符。
3. STR
- 语法格式:
1 | A |
- 功能说明:将A(A为数字量或逻辑表达式)转换成字符串。
4. LEFT
- 语法格式:
1 | A :LEFT: B |
- 功能说明:返回字符串A最左端B(B为返回长度)长度的字符串。
5. RIGHT
- 返回一个字符串最右端一定长度的字符串:
1 | A :RIGHT: B |
- 功能说明:返回字符串A最右端B(B为返回长度)长度的字符串。
6. CC
- 用于连接两个字符串,B串接到A串后面:
1 | A :CC: B |
5* 地址标号
- PC相关标号
- 寄存器相关标号
- 绝对地址
6* 局部标号
- 局部标号的语法格式如下:
1 | n {routname} |
- 被引用的局部标号语法规则是:
1 | % {F∣B} {A∣T} n {routname} |
- 其中:
- n是局部标号的数字号。
- routname是当前局部范围的名称。
- %表示引用操作。
- F指示汇编器只向前搜索。
- B指示汇编器只向后搜索。
- A指示汇编器搜索宏的所有嵌套层次。
- T指示汇编器搜索宏的当前层次。
2、GNU环境下汇编语句与编译说明
- GNU环境下ARM汇编语言程序设计主要是面对在ARM平台上进行嵌入式LINUX的开发。
- GNU标准中提供了支持ARM汇编语言的汇编器as(arm-elf-as)、交叉编译器gcc ld(arm-elf-gcc)和链接器ld(arm-elf-ld)。
(1)GNU环境下ARM汇编语句格式
- GNU环境下ARM汇编语言语句格式如下:
1 | {label :} {instruction} {@comment} |
(2)GNU环境下ARM汇编程序编译
1* 预处理
- GNU汇编器as的内部预处理包括:移除多余的间隔符代码中的所有注释,并将字符常量转换为数字值。它不作宏处理和文件包含处理,但这些事情可以交由gcc编译器去做,文件包含可以用.include伪指令来实现。
2* 注释
- GNU ARM Assembly可识别的注释方式有:
- C风格多行注释符/* … */
- GNU单行注释符“@”或“#”。
3* 符号
- 与C语言基本一致,符号名由字母、数字以及’_’、和’.’组成,大小写敏感。
4* 段与重定位
- 链接器ld用于把多个目标文件合并为一个可执行文件。
- 汇编器as生成的目标文件都假定从地址0开始,ld为其指定最终的地址。
- 链接器ld把目标文件中的每个section都作为一个整体,为其分配运行的地址

5* 符号说明
1. label
- lable后面要带冒号‘:’,例如:
1 | _start: B Reset_handler |
2. 给符号赋值
1 | symbol_name = symbol_value |
3. 符号名
- 可由数字、字母或‘.’或‘_’组成,不可以数字开头,大小写敏感。
3、ARM汇编语言程序设计规范
(1)汇编器预定义的寄存器名称
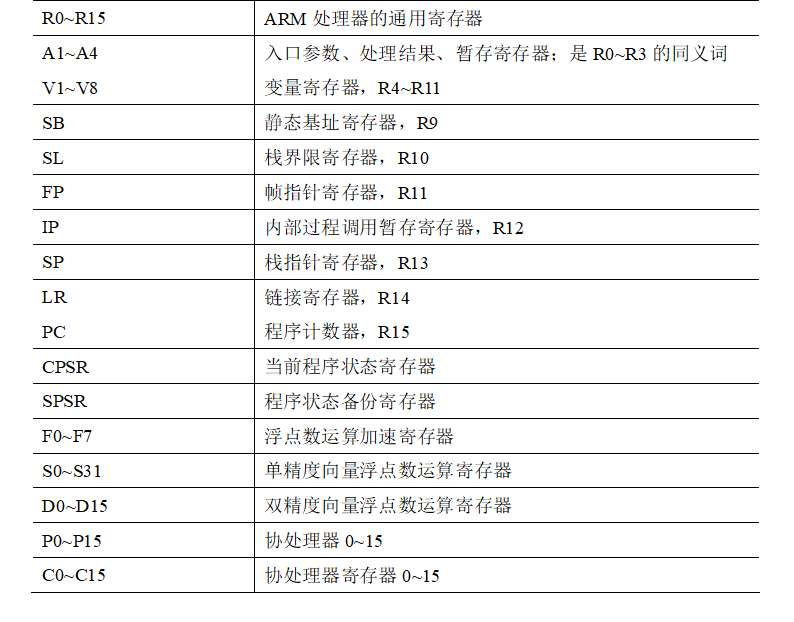
(2)ARM汇编语言程序设计规范
- 符号命名规则
- 注释
- 程序设计的其它要求
七、ARM汇编语言与嵌入式C混合编程
1、嵌入式C编程规范
- 在当前的嵌入式开发中,嵌入式C语言是最为常见的程序设计语言。
- 优秀的代码还要具备易读性、易维护性、具有可移植和高可靠性。
(1) 嵌入式C程序书写规范
排版规则如下:
程序块要采用缩进风格编写
较长的语句(例如超过80个字符)要分成多行书写
循环、判断等语句中若有较长的表达式或语句,则要进行适应的划分
若函数或过程中参数较长,也要进行适当的划分。
一般不要把多个短语句写在一行中
程序块的分界符语句的大括号“{”与“}”一般独占一行并且在同一列
(2)命名规则
- 标识符的名称要简明,能够表达出确切的含义,可以使用完整的单词或通常可以理解的缩写。
- 如果在命名中使用特殊约定或缩写,则要进行注释说明。
- 对于变量命名,一般不取单个字符 ,例如i、j、k…
- 函数名一般以大写字母开头;所有常量名字母统一用大写。
(3)注释说明
注释有助于程序员理解程序的整体结构,也便于以后程序代码的维护与升级。常用的规则如下:
注释语言必须准确、简洁且容易理解;
程序代码源文件头部应进行注释说明 ;
函数头部应进行注释;
程序中所用到的特定含义的常量、变量,在声明时都要加以注释 ;
对于宏定义、数据结构声明,如果其命名不是充分自注释的,也要加以注释。
如果注释单独占用一行,与其被注释的内容进行相同的缩进方式,一般将注释与其上面的代码用空行隔开
程序代码修改时,其注释也要及时修改,一定要保证代码与注释保持一致。
2、嵌入式C程序设计中的位运算
- 在嵌入式程序设计中,位操作是最常用的运算之一,因为在很多情况下要对寄存器中的某位或某个管脚进行操作,这些都需要用位操作来完成。
(1)按位与操作
- 按位与运算符“&”是把参与运算的两个操作数所对应的各个二进制位进行按位相与。
- 只有当对应的两个二进制位全为1时,结果才为1,否则为0。
- 参与运算的两个操作数以补码形式出现。
(2)按位或操作
- 按位或操作运算符“|”是把参与运算的两个操作数对应的各个二进制位进行按位相或。
- 对应的两个二进制位中只要有一个为1,结果就为1,当两个对应的二进制位都为0时,结果位为0。
- 参与运算的两个操作数均以补码形式出现。
(3)按位异或操作
- 按位异或运算符“^”是将参与运算的两个操作数对应的各个二进制位进行相异或。
- 当对应的两个二进制位相异时,结果位为1,相同时为0。
- 参与运算的两个操作数均以补码形式出现。
(4)取反操作
- 取反运算符“
”实现对参与运算的操作数对应的各个二进制位按位求反。取反运算符“”具有右结合性。所有1变为0,0变为1
(5)移位操作
- 移位操作分为左移操作与右移操作。左移运算符“<<”实现将“<<”左边的操作数的各个二进制位向左移动“<<”右边操作数所指定的位数,高位丢弃,低位补0。
- 其值相当于乘以:2“左移位数”次方。
- 右移运算符“>>”实现将“>>”左边的操作数的各个二进制位向右移动“>>”右边操作数所指定的位数。
- 对于空位的补齐方式,无符号数与有符号数是有区别的。对无符号数进行右移时,低位丢弃,高位用0补齐,其值相当于除以:2“右移位数”次方
3、嵌入式C程序设计中的几点说明
(1)volatile限制符
- volatile的本意为 “暂态的”或.“易变的”,该说明符起到抑制编译器优化的作用。
- 如果在声明时用“volatile”关键进行修饰,遇到这个关键字声明的变量,编译器对访问该变量的代码就不再进行优化,从而可以提供特殊地址的稳定访问。
(2)地址强制转换与多级指针
1* 地址强制转换
- 在C程序设计中,绝对地址0x0FA00只是被当成一个整型数,如果要把它当成一个地址来使用就需要进行地址强制转换。
- 如定义一个整形指针int* p,然后把绝对地址0x0FA00转换成一个整形的地址值赋给这个整形指针,p = (int* )0x0FA00。
- 因此在嵌入式程序设计中,经常可以可以看到寄存器用如下方式进行定义:
1 | #define rPCONA (*(volatile unsigned *)0x1D20000) |
2* 多级指针

(3)预处理的使用
- 在源流程序被编译器处理之前, 编译预处理器首先对源程序中的预处理命令进行展开或处理。
- 预处理命令书写格式为以“#”开头,占单独书写行,语句尾不加分号。
1* 宏定义(#define)
1. 不带参数的宏
- 不带参数的宏定义的一般形式为:
1 |
2. 带参数的宏定义
- 带参数的宏定义一般形式为:
1 |

3. 带参宏与函数的区别

2* 文件包含(#include)
- 文件包含的功能是使得一个源文件可以将另一个源文件的内容全部包含进来,它的一般形式为:
1 |
3* 条件编译
1. 形式1
1 |
|
2. 形式2
1 |
|
3. 形式3
1 |
|
4、嵌入式C程序设计格式
(1)可重入函数
- 如果某个函数可以被多个任务并发使用,而不会造成数据错误,我们就说这个函数具有可重入性(reentrant) 。
- 可重入函数可以使用局部变量,也可以使用全局变量。
- 如果使用全局变量,则应通过关中断、信号量(即P、V操作)等手段对其加以保护
(2)中断处理程序
在编写中断服务程序时需要满足如下要求:
不能向中断服务程序传递参数;
中断服务程序没有返回值;
中断服务程序应要尽可能短,来减少中断服务程序的处理时间,保证实时系统的性能。
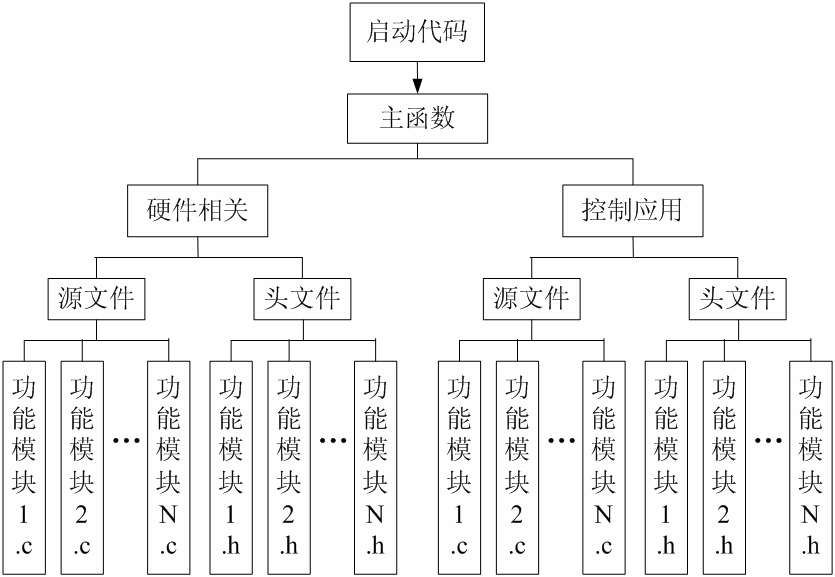
(3)模块化程序设计
- 嵌入式C程序设计主要采用模块化设计方法,将系统内的任务进行合理的划分,将具有同一属性或相同类别的代码归为一类组成模块,每个模块的功能相对独立。
- 将整个软件系统分为多个模块,编程思路就会很清晰。
5、过程调用标准ATPCS与AAPCS
- 过程调用标准ATPCS(ARM-Thumb Produce Call Standard)规定了子程序间相互调用的基本规则, ATPCS规定子程序调用过程中寄存器的使用规则、数据栈的使用规则及参数的传递规则。
- 2007年,ARM公司推出了新的过程调用标准AAPCS(ARM Architecture Produce Call Standard),它只是改进了原有的ATPCS的二进制代码的兼容性。
- 2011年,ARM公司推出了新的过程调用标准AAPCS64(ARM Architecture Produce Call Standard),针对64位架构AArch64
(1)寄存器使用规则
- 子程序间通过寄存器R0~R3传递参数,寄存器R0~R3可记作A1~A4。被调用的子程序在返回前无须恢复寄存器R0~R3的内容。
- 在子程序中,ARM状态下使用寄存器R4~R11来保存局部变量,寄存器R4~R11可记作V1~V8;Thumb状态下只能使用R4~R7来保存局部变量。
- 寄存器R12用作子程序间调用时临时保存栈指针,函数返回时使用该寄存器进行出栈,记作IP;在子程序间的链接代码中常有这种使用规则。
- 通用寄存器R13用作数据栈指针,记作SP。
- 通用寄存器R14用作链接寄存器 ;
- 通用寄存器R15用作程序计数器,记作PC 。
(2)数据栈使用规则
- 过程调用标准规定数据栈为FD类型,并且对数据栈的操作时要求8字节对齐的。
- 堆栈是一种数据结构
- 先进先出
- 使用一个堆栈指针的专用寄存器只是当前位置 * ARM 中是R13
1* 堆栈分类
根据堆栈指针的位置可以分为:
满堆栈(Full Stack):
- 当堆栈指针指向最后压入堆栈的数据时;
空堆栈(Empty Stack):
- 当堆栈指针指向下一个将要放入数据的空位置时;
根据堆栈的生成方式,又可以分为递增堆栈和递减堆栈:
递增堆栈(Ascending Stack) :
- 当堆栈由低地址向高地址生成时;
递减堆栈(Decending Stack) :
- 当堆栈由高地址向低地址生成时;
2* 块拷贝与栈操作的对应关系
(3)参数传递规则
1* 参数个数可变的子程序参数传递规则
- 对于参数个数可变的子程序,当参数个数不超过4个时,可以使用寄存器R0~R3来传递;当参数个数超过4个时,还可以使用数据栈进行参数传递。
2* 参数个数固定的子程序参数传递规则
- 如果系统不包含浮点运算的硬件部件且没有浮点参数时,则依次将各参数传送到寄存器R0~R3中,如果参数个数多于4个,将剩余的字数据通过数据栈来传递;
- 如果包括浮点参数则要通过相应的规则将浮点参数转换为整数参数,然后依次将各参数传送到寄存器R0~R3中。如果参数多于4个,将剩余字数据传送到数据栈中,入栈的顺序与参数顺序相反,即最后一个字数据先入栈。
- 如果系统包含浮点运算的硬件部件,将按照如下规则传递:
- 各个浮点参数按顺序处理
- 为每个浮点参数分配寄存器。分配方法是:找到编号最小的满足该浮点参数需要的一组连续的FP寄存器进行参数传递。
3* 子程序结果返回规则
- 结果为一个32位的整数时,通过寄存器R0返回;结果为一个64位整数时,通过寄存器R0,R1返回。
- 结果为一个浮点数时,可以通过浮点运算部件的寄存器F0、D0或者S0来返回;结果为复合型的浮点数(如复数)时,可以通过寄存器F0~Fn或者D0~Dn来返回。
- 对于位数更多的结果,需要通过内存来传递。
6、ARM汇编语言与嵌入式C混合编程
- 在嵌入式程序设计中,有些场合(如对具体的硬件资源进行访问)必须用汇编语言来实现,可以采用在嵌入式C语言程序中嵌入汇编语言或嵌入式C语言调用汇编语言来实现。
(1)内嵌汇编
1* ARM开发工具编译环境下内嵌汇编语法格式

2* GNU ARM环境下内嵌汇编语法格式

3* 内嵌汇编的局限性
- ARM开发工具编译环境下内嵌汇编语言,指令操作数可以是寄存器、常量或C语言表达式。可以是char、short或int类型,而且是作为无符号数进行操作。
- 当表达式过于复杂时需要使用较多的物理寄存器,有可能产生冲突。
- GNU ARM编译环境下内嵌汇编语言ARM开发工具稍有差别,不能直接引用C语言中的变量。
1. 物理寄存器
- 不要直接向程序计数器PC赋值,程序的跳转只能通过B或BL指令实现。
- 一般将寄存器R0~R3、R12及R14用于子程序调用存放中间结果,因此在内嵌汇编指令中,一般不要将这些寄存器同时指定为指令中的物理寄存器。
- 在内嵌的汇编指令中使用物理寄存器时,如果有C语言变量使用了该物理寄存器,则编译器将在合适的时候保存并恢复该变量的值。需要注意的是,当寄存器SP、SL、FP以及SB用作特定的用途时,编译器不能恢复这些寄存器的值。
- 通常在内嵌汇编指令中不要指定物理寄存器,因为有可能会影响编译器分配寄存器,进而可能影响代码的效率。
2. 标号、常量及指令展开
- C语言程序中的标号可以被内嵌的汇编指令所使用。但是只有B指令可以使用C语言程序中的标号,BL指令不能使用C语言程序中的标号。
3. 内存单元的分配
- 内嵌汇编器不支持汇编语言中用于内存分配的伪操作。所用的内存单元的分配都是通过C语言程序完成的,分配的内存单元通过变量以供内嵌的汇编器使用。
4. SWI和BL指令
- SWI和BL指令用于内嵌汇编时,除了正常的操作数域外,还必须增加如下3个可选的寄存器列表:
- 用于存放输入的参数的寄存器列表。
- 用于存放返回结果的寄存器列表。
- 用于保存被调用的子程序工作寄存器的寄存器列表。
4* 内嵌汇编器与armasm汇编器的区别
- 内嵌汇编器不支持“LDR Rn, = expression”伪指令,使用“MOV Rn, expression”代替,不支持ADR、ADRL伪指令
- 十六进制数前要使用前缀0x,不能使用&。当使用8位移位常量导致CPSR中的ALU标志位需要更新时,N、Z、C、V标志中的C不具有实际意义
- 指令中使用的C变量不能与任何物理寄存器同名,否则会造成混乱
- 不支持BX和BLX指令
- 使用内嵌汇编器,不能通过对程序计数器PC赋值,实现程序返回或跳转。
- 编译器可能使用寄存器R0~R3、R12及R14存放中间结果,如果使用这些寄存器时要特别注意。
(3)ARM汇编语言与嵌入式C程序相互调用
1* 汇编程序调用C程序
- 在GNU ARM编译环境下,汇编程序中要使用.extern伪操作声明将要调用的C程序;
- 在ARM开发工具编译环境下,汇编程序中要使用IMPORT伪操作声明将要调用的C程序。
2* C程序调用汇编程序
- 在GNU ARM编译环境下,在汇编程序中要使用.global伪操作声明汇编程序为全局的函数,可被外部函数调用,同时在C程序中要用关键字extern声明要调用的汇编语言程序。
- 在ARM开发工具编译环境下,汇编程序中要使用EXPORT伪操作声明本程序可以被其他程序调用。同时也要在C程序中要用关键字extern声明要调用的汇编语言程序。
八、S3C44B0/S3C2410通信与LCD接口技术
S3C44B0/ S3C2410 UART
- 通用异步接收和发送UART(Universal Asynchronous Receiver and Transmitter)协议作为一种低速通信协议,广泛应用于通信领域的各种场合。
(1)UART原理
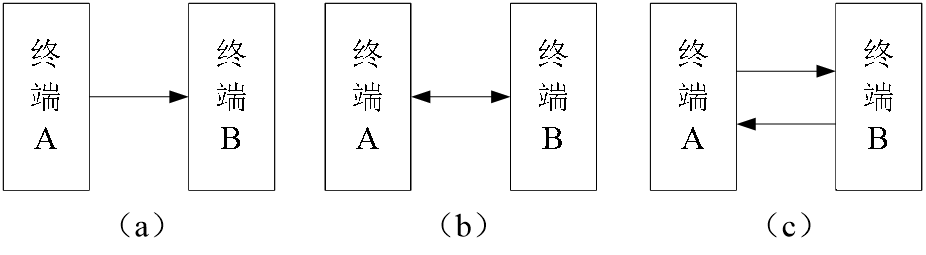
1* 串行通信的工作方式
2* 串行通信的波特率
- 在串行通信中,用波特率来描述数据的传输速度。波特率是每秒钟传送的二进制位数,其单位是bps(bits per second)。
- 是衡量串行数据速度快慢的重要指标。异步串行通信要求通信双方的波特率必须相同。
3* 奇偶校验
- 在发送数据时,每个数据后要附加1个奇偶校验位,这个校验位可以为1也可以为0,用来保证包括奇偶校验位在内的所有传输的数据帧中1的的个数为奇数(奇校验)或1的个数为偶数(偶校验)。
4* 数据帧格式

(2)S3C44B0/ S3C2410 UART模块
- S3C44B0的UART单元提供两个独立异步串行I/O(SIO)端口,S3C2410的UART提供3个独立异步串行I/O,每一个可以在基于中断和基于DMA的模式下操作。
- S3C44B0的UART可以支持位速率高达115.2K bps,S3C2410的UART可支持高达230.4K bps。每个UART通道包含两个16字节先进先出缓存(FIFO),负责数据的接收和发送。
(3)S3C44B0/ S3C2410 UART操作
1* 数据发送与接收
- 它包括一个起始位,5
8个数据位,一个可选的奇偶校验位和12个停止位,用户可以通过线控制寄存器(ULCONn)的编程来设定。 - 在数据传输完成后产生传输中止信号,在中止信号传输后,可以继续向Tx FIFO(或在非FIFO模式下的Tx 保持寄存器)中发送数据。
2* 自动流量控制(AFC)
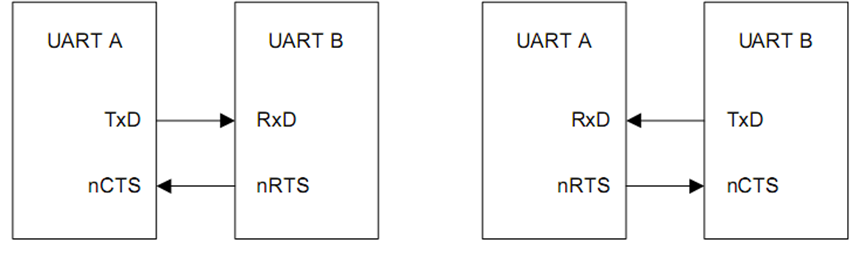
- S3C44B0和S3C2410支持带有nRTS和nCTS信号的自动流量控制。如果希望连接UART到调制解调器,禁止UMCONn寄存器的自动流量控制位,然后通过软件控制nRTS的信号。
3* 自环模式
- S3C44B0/S3C2410提供一个测试模式称为自环模式,以解决在通信连接时的错误。在此模式下,发送的数据被直接接收。
4* 红外模式
S3C44B0/S3C2410的UART模块支持红外(IR)发送和接收,可以通过设置UART控制寄存器中的红外模式位选定
当IR处于发送模式时,如果输送的的数据位为0,传输周期是正常串口传输的3/16脉冲;当IR处于接收模式时,接收器必须侦测3/16脉冲周期来识别一个0值。
(4)UART中断与波特率的计算
1* UART中断
- S3C44B0/S3C2410每个UART有7个状态信号:超时错误、奇偶错误、帧错误、通信中止、接收数据缓冲区就绪、发送数据缓冲区为空和发送移位寄存器为空
2* 波特率的产生

(5)S3C44B0/ S3C2410 UART专用功能寄存器
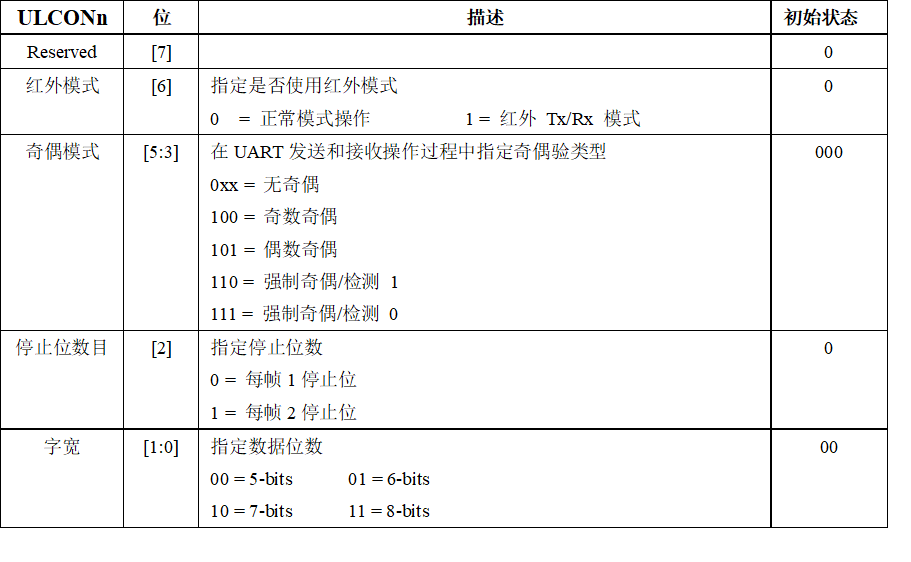
1* UART线控制寄存器(ULCONn)
S3C44B0有2个UART线控制寄存器,ULCON0和ULCON1。
S3C2410有三个UART控制寄存器,ULCON0,ULCON1和ULCON2。

2* UART控制寄存器UCONn
S3C44B0有2个UART控制寄存器:UCON0和UCON1。
S3C2410有三个UART控制寄存器:UCON0,UCON1和UCON2。


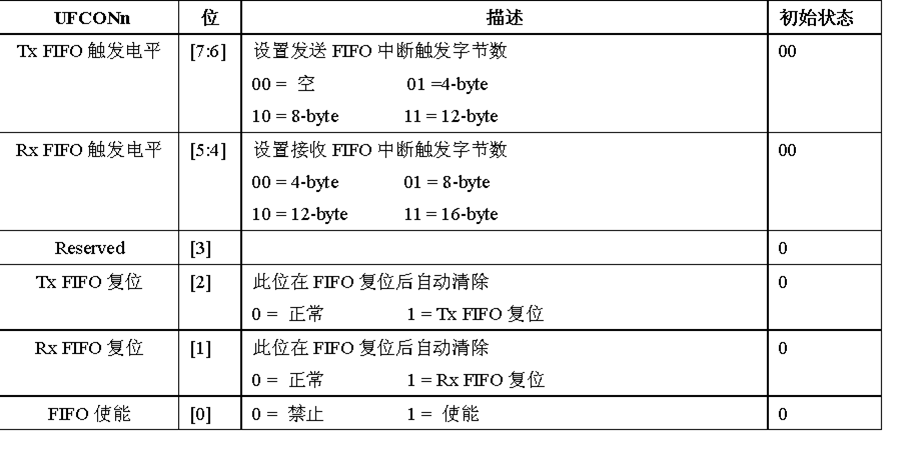
3* UART FIFO控制寄存器
S3C44B0有2个UART FIFO控制寄存器:UFCON0和UFCON1。
S3C2410有3个UART FIFO控制寄存器:UFCON0,UFCON1和UFCON2。

4* UART调制解调器控制寄存器
- S3C44B0有2个UART调制解调器控制寄存器,UMCON0和UMCON1。
- S3C2410有3个UART调制解调器控制寄存器:UMCON0,UMCON1和UMCON2。
5* UART 发送/接收状态寄存器
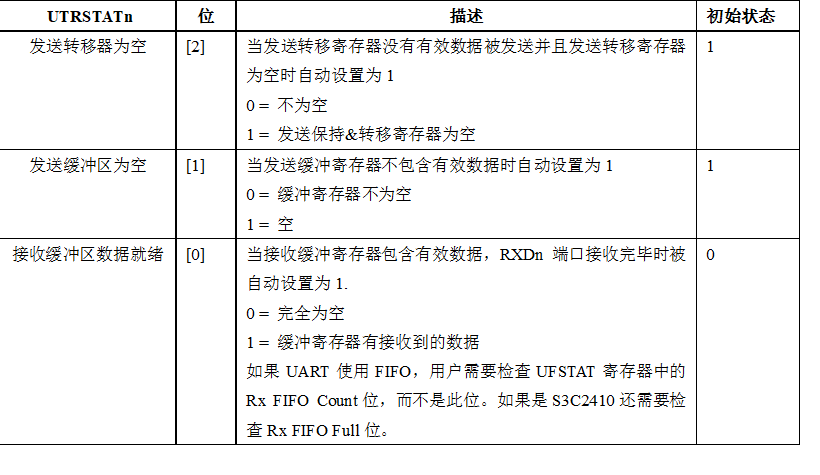
S3C44B0有2个UART发送/接收状态寄存器:UTRSTAT0和UTRSTAT1。
S3C2410有3个UART发送/接收状态寄存器:UTRSTAT0,UTRSTAT1和UTRSTAT2。

6* UART错误状态寄存器
- S3C44B0有2个UART错误状态寄存器:UERSTAT0和UERSTAT1。
- S3C2410有3个UART错误状态寄存器:UERSTAT0,UERSTAT1和UERSTAT2
7* UART FIFO状态寄存器
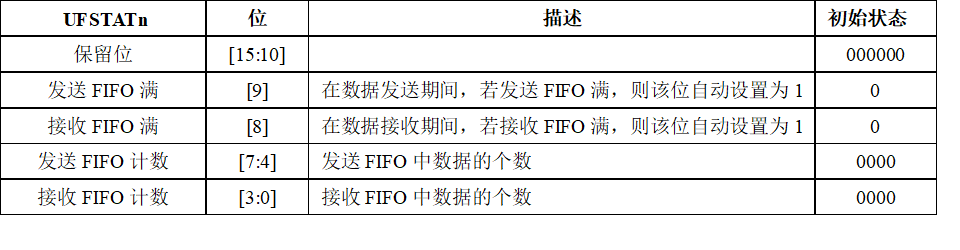
S3C44B0有2个UART FIFO状态寄存器:UFSTAT0和UFSTAT1。
S3C2410有3个UART FIFO状态寄存器:UFSTAT0,UFSTAT1和UFSTAT2。

8* UART 调制解调器状态寄存器
- S3C44B0有2个UART调制解调器状态寄存器:UMSTAT0和UMSTAT1。
- S3C2410也有2个UART调制解调器状态寄存器:UMSTAT0和UMSTAT1
9* UART 发送缓冲寄存器
S3C44B0有2个UART发送缓冲寄存器:UTXH0和UTXH1。
S3C2410也有3个UART发送缓冲寄存器:UTXH0、UTXH1和UTXH2。


10* UART 接收缓冲寄存器
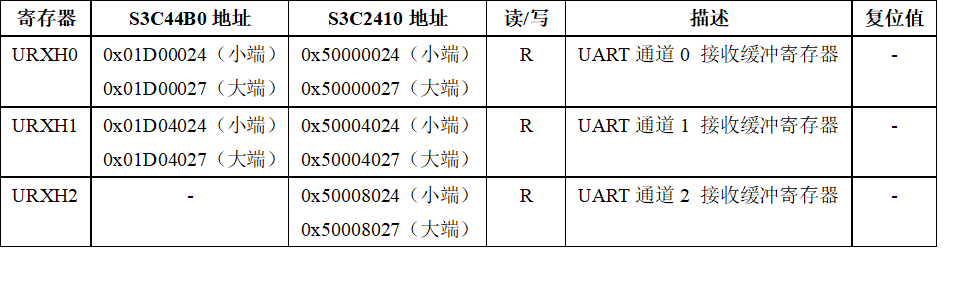
S3C44B0有2个UART发送缓冲寄存器:URXH0和URXH1。
S3C2410也有3个UART发送缓冲寄存器:URXH0、URXH1和URXH2。

九、实验源码
- 对内存地址0X3000开始的100个字内单元填⼊0X10000001—-0X10000064,将每个字单元进⾏64位累加,结果送⼊其后容闲内存单元
1 | exp,, |
2. 实现整数除法123/22,得出商和余数。
1 | exp,, |
3. 将R0中的数据调换顺序 * 例如: R0=0xAABBCCDD调换顺序后R0=0xDDCCBBAA
1 | AREA exp,CODE,READONLY |
4. 将整数数组 {0xAABBCC11,0xAABBCC00,0xAABBC
C33,0xAABBCC22,0xAABBCC44}进⾏选择排序。
1 | exp,, |
5. 使用汇编语言调用 C 语言实现 20!。
- test.s
1 | test |
- main.c
1 | long long CFUN(int a) |
6. 使用汇编语言调用 C 语言实现 5 个数(5,7,9,11,13)加法。
- addl.s
1 | ADDL,, |
- main.c
1 | int CAL(int a,int b,int c, int d, int e) |
7. 使用C语言调用汇编语言实现 21!。
- test.s
1 | test,, |
- main.c
1 | extern void Factorial(char x); |
8. 使用C语言调用汇编语言实现 5 个数(5,7,9,11,13)加法。
- test.s
1 | test,, |
- main.c
1 | extern void Add(char a,char b,char c,char d,char e); |